
During the Finnish Municipal elections (2017) we had Suomen Kuvalehti, a leading Finnish news magazine, as a client. We were helping them to analyse and visualise the data collected by YLE, Finland’s national public-broadcasting company, and Suomen Kuvalehti. The data was collected from a voting advice application and is available here.
The main goal was to visualise what kind of promises the candidates were making, because in Finnish municipal election system those matter more than the declarations of the political parties the candidates represent.
Our first analysis was frequency analysis and visualisation of words used in the language by the candidates. The example above contains the visualisation for the Green League party in Finland. Our second analysis was to find deeper insights from the data: actual, concrete promises instead of just common words.

Unfortunately, the second part of our work was not published in the magazine due lack of time — however, we’d like to tell you about it here as it was well received by the researchers at Suomen Kuvalehti and also showcases advanced topics in analysing natural language.
Finnish is hard, especially for computers
We first tried to analyse the text formatted promises of the 15 000 candidates by simply doing TF-IDF but found out soon it wouldn’t be enough for finding the most significant things or differences. Even extending the frequency analysis into bigrams or trigrams gave us bad results so it was time to improvise.
Our previous experiments had pointed out that most of the candidates preferred to use sentence structures like ‘I promise to make …’ or ‘I want to make sure that …’ and so we thought that maybe some NLP could help us out to find the facts for us.
Finnish language is said to be one of the most complicated languages in the world and in fact, it is very hard to analyse with computers. Fortunately Turku BioNLP group from University of Turku has made a surprisingly good open source dependency parsing pipeline for Finnish language.
In our analysis, we started by annotating all textual content with the dependency parser. The parser outputs CoNLL-U-formatted annotation file so the next step was to parse that into something a bit more usable.
Understanding relations between words

Following screenshot is visualising the parse tree of Finnish sentence “Lupaan edistää lasten, nuorten ja perheiden asioita sekä huomioida heidän etunsa päätöksenteossa.” (I promise to promote issues of the children, young and families and take care of their interests in decision making.)
To extract the facts that the promise is about (interests of children, interests of young and interests of families) we needed to inspect the relationships between the words.
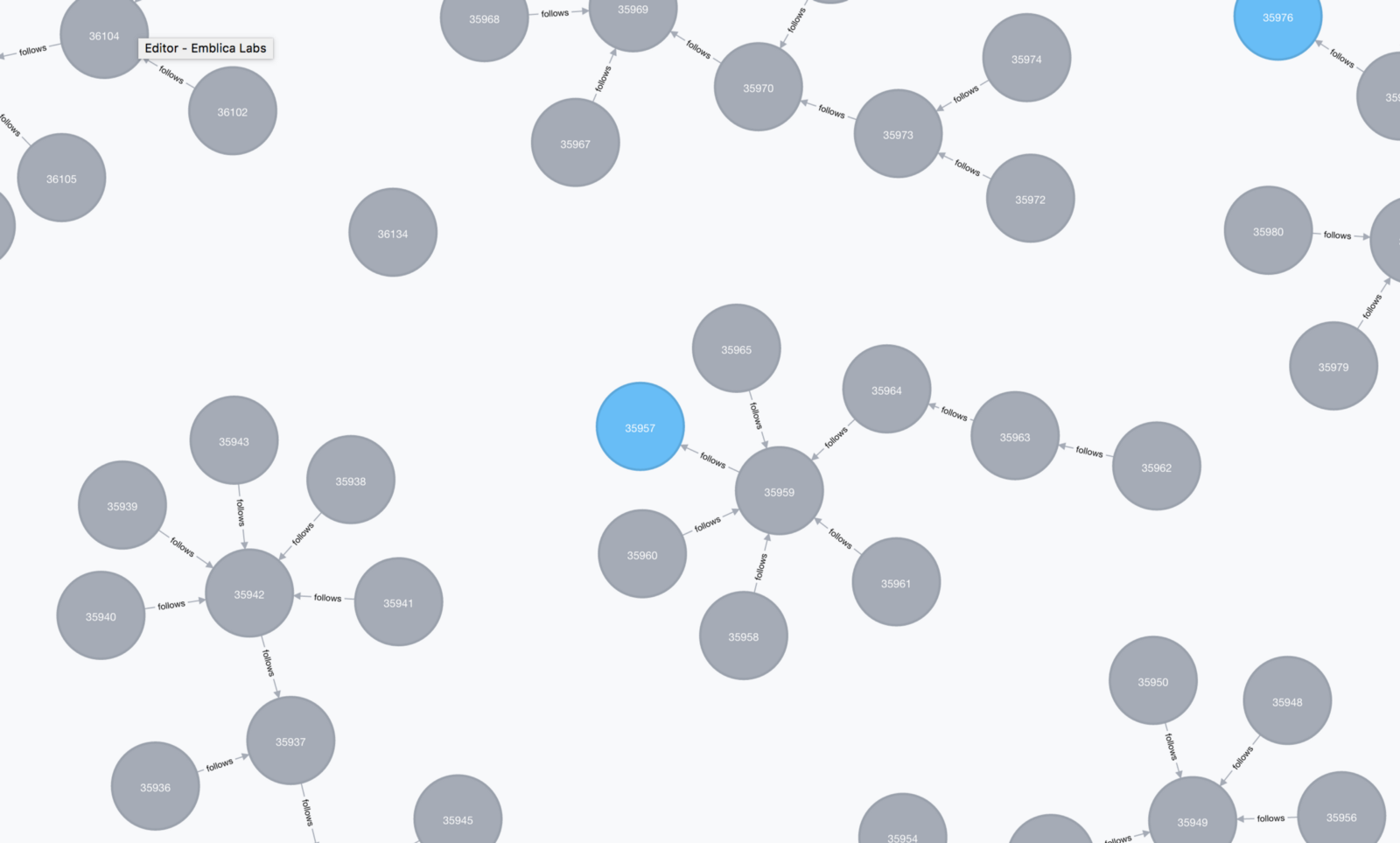
Although there are some query tools for annotated language data we selected a graph database so we could use familiar query syntax to query complex relationships between syntactic entities in sentences.
In addition to a familiar query language, the Neo4j graph database offers a great user interface for discovering and exploring the relations so we ingested all the data into that.
Graph queries ease up finding facts from parsed natural language
Neo4j provides a very useful tool for inspecting the contents of a database, making queries and looking for the query results.
By using the Neo4j’s user interface, exploring and running queries against the data was very interactive and fast. This is very helpful when working with journalists, who had good domain knowledge but bad technical knowledge while the opposite was true for us. We were able to quickly iterate on different kinds of questions about the dataset.
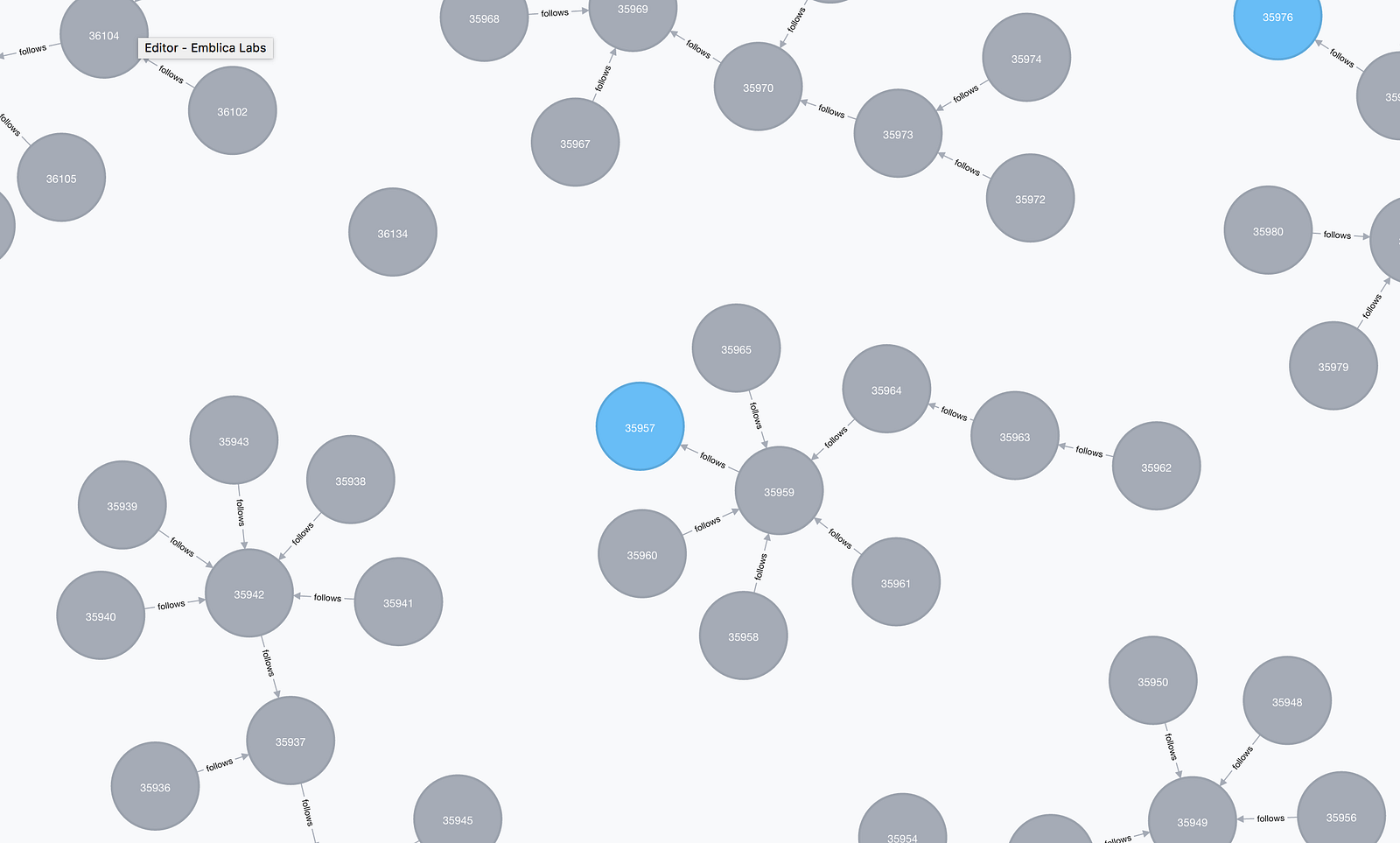
We can inspect the structure of parsed sentences by just clicking around in the UI but the interesting part is to actually make queries from the data.
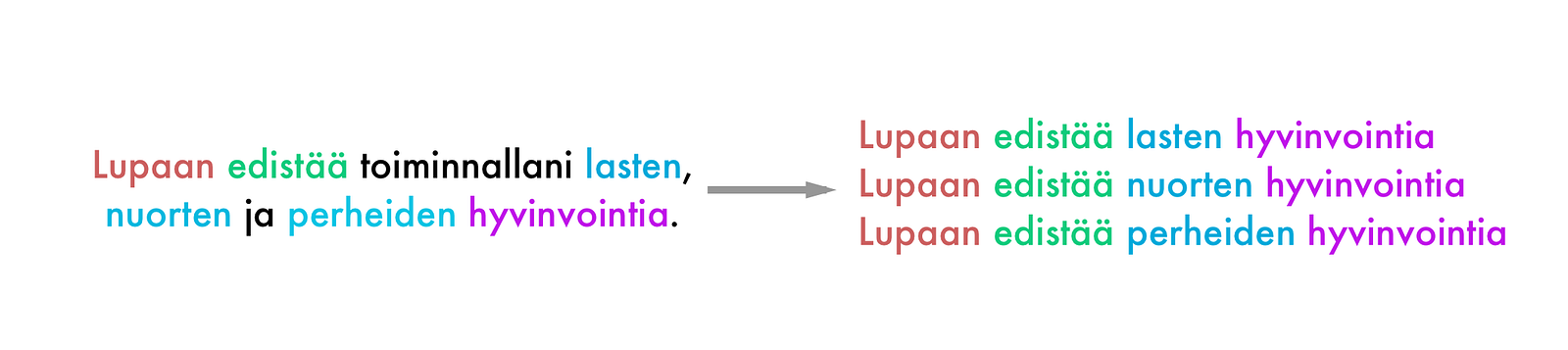
We searched for patterns that we could use as ‘facts’ about some promise. One such pattern was a verb followed by another verb in open clausal complement relation followed by the nominal subject to those verbs, we could use the sentence formed by those words as a ‘fact’. An example of a pattern like this would be: I promise to improve well-being of families. Where “promise” and “improve” are the verbs and “well-being of families” is the nominal subject.
We also made sure that the adjectives or negations are taken care of so that ‘I like dogs’ and ‘I don’t like dogs’ are two different things. From those patterns we made cypher queries (Neo4j’s query language) and so we had the facts about the promises to use in further analysis.
Links and acknowledgement
Paywall free link to the Suomen Kuvalehti article.
Thanks for Milka Valtanen who wrote the article based on the data, Hannu Kyyriäinen for the post processing of the wordclouds and Tuomas Pulsa for shuffling things around and making the communication easier.