
In 2016 Norppalive was one of the most searched term from Google in Finland in whole year. The concept is simple: One camera is streaming a live stream from one of the stones in Saimaa and people all around the world can try to see one of the rarest seals in the world.
Then I was already interested for applying modern computer vision to track when the seal is actually in the picture and tweet about that. However due lack of time I didn’t ever do that, but the idea lived over.
In this spring 2017, WWF announced they are going to have the same stream available this year too and I felt like I could finally try it out and make a Twitter-bot for watching the stream.
When you are applying machine learning to some problem there is many ways to achieve the target — in this case to detect if there is a seal or not. Naive approach could be for example to find out differences between the two frames from the video stream and so detect if there is a change (and possibly seal) but that might have problems with changing light conditions.
You could also track if there are moving targets but once again its prone to errors. Baseline when selecting the technology is that usually you want to take the easiest and shortest path because it’s almost always also the cheapest one. However I wanted to discover the performance of modern deep learning networks and so I didn’t have to take care of that.
Good CS expert says: Most firms that thinks they want advanced AI/ML really just need linear regression on cleaned-up data.
— Robin Hanson (@robinhanson) November 28, 2016
One option to use modern deep learning networks very quickly is to use some SaaS provider such as Amazon or Google and their APIs. With that option you could get very good results and in many cases it doesn’t even cost a lot to you. However the cons are that you will have to send your own data to third party, which might be not tolerable when dealing with some data such as customer personal details, also you are in the same line with everybody else. You are using a “ready” product and so everyone gets the updates to model but your own modifications for the model are impossible with current providers.
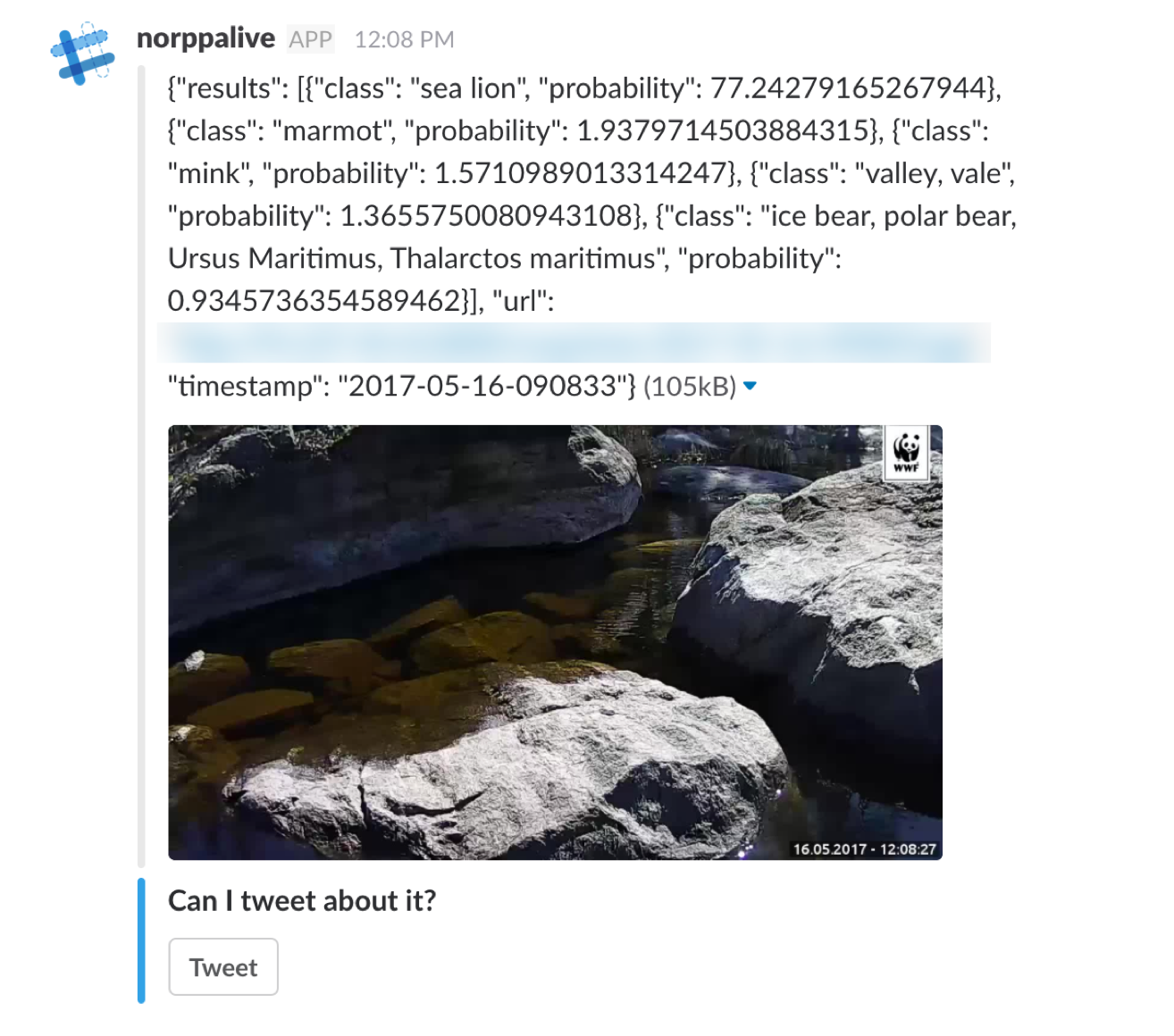
My approach was to take machine learning framework called Tensorflow and use already defined architecture of deep convolutional image classification network called Inception and use it with pre-trained ‘brains’ from Google.
When you’re using a pre-trained deep convolutional network, you will get a classifier that has knowledge of millions of images already and some thousands of categories it can classify new images you show to it. This is almost the same that what you get from those commercial APIs by using some SaaS, but you also have room to break out and make all modifications you want to do. If you’re training your own model from scratch you will have to have massive amounts of computing capability and training material to achieve same level of accuracy.
Transfer learning makes general models to suit your specific use case
The problem with pre-trained models is that they are usually too general to use in any specific problem but on the other hand training the deep neural network from scratch is not cost efficient and sometimes in lack of proper training data just impossible. There is another method to achieve good results even with small corpus of training data, called transfer learning.
The basic idea behind transfer learning is to first train the network to have general image classifying capability with huge amounts of training samples and labels. After that you can modify the pre-trained network to fill your specific use case by just training simpler layers on top of the complex network. In my case the problem reduced just to recognise if there is a seal in picture or not.
Even though the required dataset to retrain is smaller than the set needed to pre-train the network, it is still something that needs to take care of. I didn’t have any training set in the beginning so I just started to collect the frames of the stream in hope of seeing the seal. I also bolted the pre-trained network in front of the stream so I could potentially see some anomalies and label them for the training. I also collected some creative commons licensed training data from Flickr to validate my model and prevent overfitting.
Don’t trust the computers, evaluate them
I wanted to tweet already from day one if there was a seal but because I didn’t have any idea how the pre-trained network will perform I made Slackbot to tell me if the network have seen something in stream with high probability and my ask my permission to tweet about it. Sometimes environment such as sunlight flickering from the water surface can cause some false positives and those are probably not what you want to tweet about.
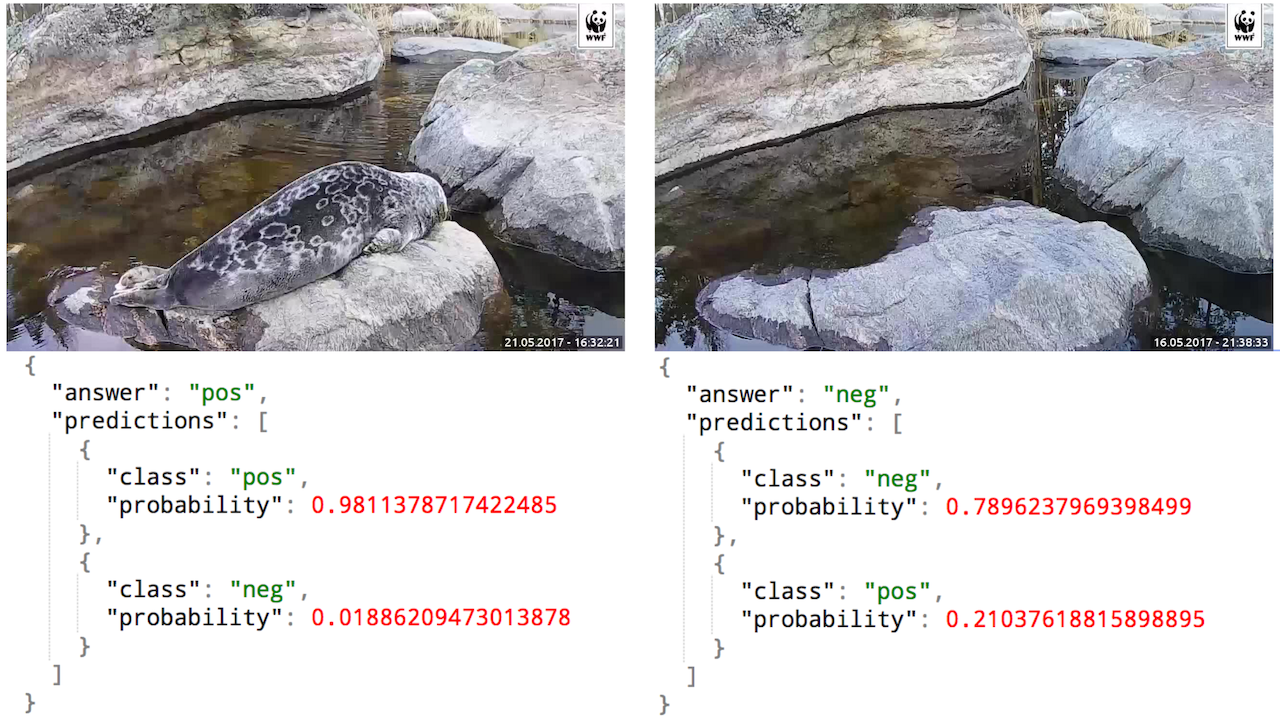
Finally after over week the seal made his first proper appearance since the stream was opened and enjoyed bathing in the sun whole day. That was very important because now I could retrain the last layers of the network to do binary classification between positive (seal on the stone) and negative (no seals on the stone). As always when dealing with any statistics you want to be sure the training data is high quality and so after getting the training data I made some visualisation what kind of samples do I have, how to make as diverse dataset as possible and how to split both, the positive and the negative frames into training and validating datasets. This is very important so you can evaluate and cross-validate your models performance during and after the training.
After that it was very easy to replace the outermost logistic layer and retrain it with new data. Now instead of the thousand pre-trained classes the classifier only knows two, but the mean error has greatly decreased and I’m finally able to trust the model after short screening phase with the “tweet-switch”.
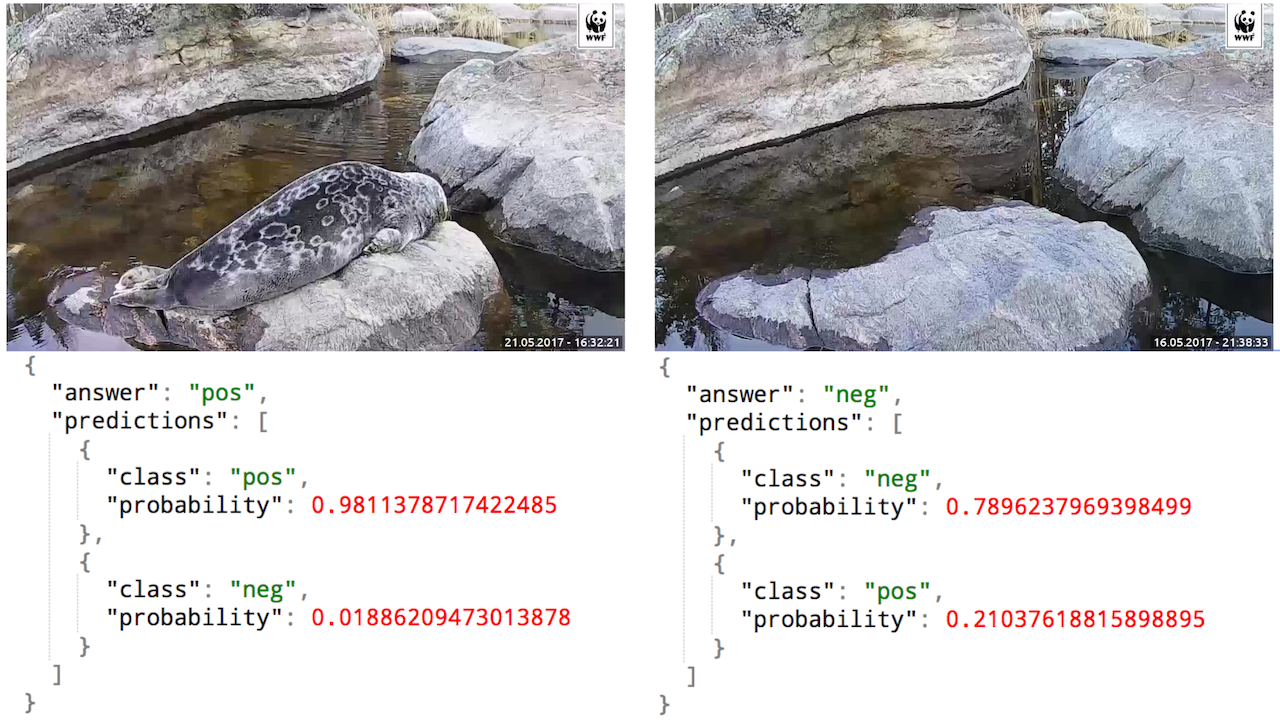
To achieve good results with new methods you have to know when to stick with some old and proven technology and when to go wild. You should also test your assumptions and new fancy things with the help of humans, because usually the processes already exists and if you can get your costs down even with slight help from computers it’s worth it.