

Briefly in English: Reading and understanding the text are two different things. This blog tells how Natural Language Processing (NLP) and other machine learning methods can help when dealing with large text materials.
Mitä on NLP?
Kuvittele että työsi olisi lukea päivästä toiseen tekstejä, dokumentteja tai artikkeleita, ja analysoida niiden sisältöä. Tehtävänäsi on esimerkiksi ohjata asiakaspalautteita tai kehitysehdotuksia eteenpäin oikeille tahoille niiden sisällön perusteella. Jos palautteita tulee tuhansia päivittäin, ehtisitkö tekemään mitään muuta niiden lukemiselta? Vai antaisitko mieluummin tietokoneen auttaa, jotta voit itse keskittyä muihin hommiin, kuten itse kehitystyöhön?
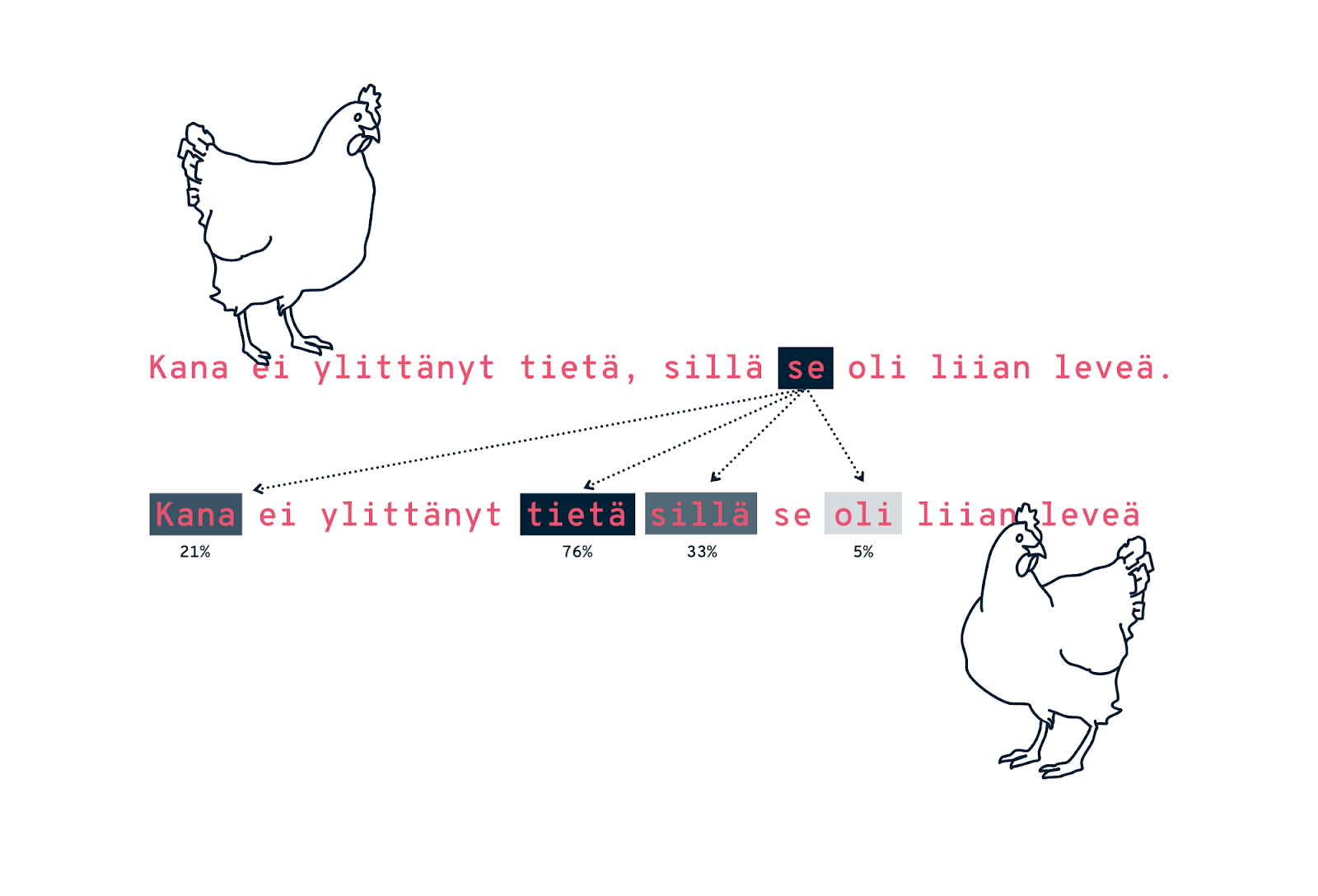
Mutta hetkinen, tietokonehan ymmärtää vain ykkösiä ja nollia, miten se osaisi lukea ja tulkita luonnollista kieltä? Tämä on ihan validi kysymys, sillä kielessä on paljon monimerkityksellisyyttä ja eri vivahteita, joille on vaikeaa tehdä tarkkoja sääntöjä ja algoritmeja. Otetaan esimerkiksi virke “Kana ei ylittänyt tietä, sillä se oli liian leveä.” Jos algoritmille annetaan säännöksi, että pilkun jälkeinen “se” viittaa aina juuri ennen pilkkua olevaan tekijään (tässä tapauksessa tiehen), mikähän olisi algoritmin tulkinta virkkeestä “Kana ei ylittänyt tietä, sillä se oli liian väsynyt”? Tekstin tulkitseminen sääntöjen avulla toimii yksinkertaisissa ja suppeissa syötteissä, kuten lomakevastauksissa, mutta NLP-tekniikoiden avulla saadaan tietokone ymmärtämään myös leveät tiet ja väsyneet kanat.
NLP:ssä käytetään paljon kielimalleja ja sanavektoreita. Kielimallit kertovat esimerkiksi todennäköisyyksiä sanoille eri lauseyhteyksissä, tai lauseille suuremmassa asiayhteydessä. Näiden todennäköisyyksien avulla voidaan sitten arvioida kielen merkitystä. Kielimalleja voidaan opettaa esimerkiksi tilastollisilla menetelmillä, tai neuroverkoilla, jotka toimivat parhaiten jos käytössä on paljon tekstiä mallin opettamiseen.
Sanavektorit taas ovat sanojen moniulotteinen, numeerinen esitysmuoto, jonka ansiosta tietokone voi hahmottaa sanojen välisiä yhteyksiä useiden ominaisuuksien perusteella. Esimerkiksi “päivä” ja “yö” ovat molemmat vuorokaudenaikoja eli lähellä toisiaan, mutta toisaalta toistensa vastakohtia eli kaukana toisistaan. Vektoriesityksen avulla tällaiset ulottuvuudet ja merkityserot on mahdollista esittää numeroina, eli tietokoneen ymmärtämässä muodossa. Myös sanavektoreita muodostetaan neuroverkkojen ja isojen tekstiaineistojen avulla.
Jo pariin otteeseen mainitut neuroverkot koostuvat laskennallisista kerroksista ja painoarvoista, jotka mahdollistavat edellä mainittujen todennäköisyyksien tai vektoreiden oppimisen. Kun neuroverkon kerrosten läpi suodatetaan isoja määriä tekstiä tarpeeksi monta kertaa, painoarvot asettuvat vastaamaan aineistona käytetyn tekstin ominaisuuksia.
Tästä päästäänkin opetusaineiston valintaan. Koska aineistoa tarvitaan paljon, yleensä käytetään internetistä löytyviä eri lähteitä kuten Wikipedia-artikkeleita ja keskustelupalstojen sisältöjä. Täytyy kuitenkin muistaa, että tekstit ovat ihmisen luomia, joten ihmisten keskuudessa esiintyvät vinoumat ja rakenteelliset eriarvoisuudet ovat läsnä myös näissä tekstiaineistoissa. Opetusaineiston vinoumia on käytännössä mahdotonta kokonaan välttää, mutta niiden tiedostaminen ja huomioonottaminen prosessin eri vaiheissa mahdollistaa käyttökelpoisten mallien kouluttamisen.
Kun kielimallilla on kieli yleisesti hallussa, voidaan se hienosäätää haluttua tehtävää varten. Neuroverkon virittäminen asiakaspalautteiden luokitteluun voi onnistua pienelläkin määrällä tehtävään sopivia, valmiiksi luokiteltuja palautteita. Tämä säästää resursseja, kuten aikaa ja laskentatehoa, ja on sitä kautta myös ekologisempaa kuin kouluttaa joka tehtävään oma mallinsa isolla määrällä dokumentteja.
Millaisia tosielämän NLP-ratkaisut sitten ovat? Seuraavaksi kolme esimerkkiä Emblican tekemistä sovellutuksista.
Automaattinen taustatoimittaja (Suomen Kuvalehti)
Eräs journalismin aikaavievimmistä työvaiheista on taustatoimittaminen.
Jotta juttu voidaan tehdä hyvin on sen taustoja pengottava huolella. Ihmistyönä tämä tarkoittaa kymmenien tai jopa satojen lähteiden lukemista ja mielenkiintoisten yhteyksien ja asioiden huomaamista. NLP on oiva apuri tähän hommaan, sillä koneelle voi syöttää tuhansia lähteitä eikä sen pää mene siitä pyörälle.
Mutta miten automaattinen taustatoimittaja osaa poimia aineistosta relevantit lähteet? Eräs NLP:n osa-alue on huomata tekstistä entiteettejä (engl. Named Entity Recognition) kuten nimiä, paikkoja, kellonaikoja ja muita vastaavia yksityiskohtia. Kun nämä yksityiskohdat poimitaan tekstistä ja analysoidaan niiden välisiä riippuvuussuhteita, voidaan löytää mielenkiintoisia yhteyksiä esimerkiksi poliitikoiden ja päättäjien välillä.
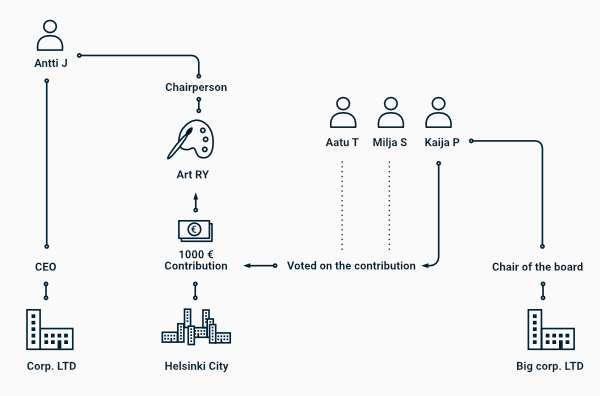
Corby on älykäs hakukone, joka toimii edellä kuvatulla tavalla. Se auttaa journalisteja taustatutkimustyössä ja säästää heidän aikaansa. Journalismin ulkopuolella samaa menetelmää voitaisiin käyttää esimerkiksi tehtaan poikkeamaraporttien käsittelyssä, asiakaspalautteiden analysoinnissa tai vaikkapa translitteröidyn puhelun automaattisessa käsittelyssä.
Valtioneuvoston kanslia
Valtioneuvoston kanslialla on monenlaisia tekstiaineistoja, kuten hallitusohjelmia eri hallitusten ajoilta. Näistä haluttiin analysoida, millaisia aiheita eri hallitukset ja puolueet ovat käsitelleet ja painottaneet eri kausilla, sekä poimia trendejä ja eroavaisuuksia hallitusten välillä. Onko ilmastoon liittyvä keskustelu kasvanut ajan myötä? Mitkä hallitukset ovat erityisesti korostaneet koulutusta hallitusohjelmissaan? Ihmisellä menisi päivä jos toinenkin kaiken aineiston lukemiseen, ja aihepiirien arvioiminen olisi siltikin vaikeaa ja kenties objektiivista. NLP:n avulla aineisto saatiin analysoitua nopeasti, kattavasti ja puolueettomasti.
Dokumenttien tekstit esikäsiteltiin ensin koneoppimismallille sopiviksi syötteiksi, ja sen jälkeen käytettiin aihemallinnusta (engl. Topic modeling) erilaisten aihepiirien tutkimiseen. Samoin kuin aiemmin mainituissa kielimalleissa, myös aihemallinnuksessa koneoppimismalli hahmottaa luonnollista kieltä todennäköisyyksien avulla. Käytännössä malli siis kertoo, kuinka todennäköisesti aineiston sanat selittyvät tietyillä aiheilla. Aiheisiin liittyvien sanojen määrä kertoo siitä, kuinka suosittuja aiheet ovat olleet. Jotta ihmisen olisi helppo hahmottaa mallin tuloksia, aiheet visualisoitiin kuvaajiksi, joista on helppo analysoida kehitystä ajan yli, tai vertailla eri hallitusten painotuksia.
Aiheiden koon lisäksi tarkastetiin myös niiden kontekstia. Millaisilla sanoilla ja lauseilla ilmastosta on keskusteltu, ja miten keskustelu on muuttunut ajan saatossa? Tähän käytettiin esimerkiksi aiemmin kuvattuja sanavektoreita, ja samalla periaatteella toimivia lausevektoreita. Niiden avulla toisiaan lähellä olevia sisältöjä voitiin visualisoida ja nähdä, olivatko sisällöt pysyneet samanlaisina vai muuttaneet suuntaa.
Kun dokumenttien esikäsittely ja aiheiden mallinnus on kerran tehty, voidaan samanlainen analyysi toistaa vaikkapa vuosittain helposti “nappia painamalla”. Näin saadaan lisää tietoa siitä, mitkä aiheet pysyvät pinnalla ja miten eri puolueista koostuvat hallitukset painottavat eri aiheita.
Trumpin tweetit (Suomen Kuvalehti)
Presidenttikautensa aikana Donald Trump oli ahkera twitterin käyttäjä. Vaikka tweetit ovatkin lyhyitä tekstinpätkiä, olisi Trumpin kymmenien tuhansien tweettien lukeminen ja analysoiminen ihmiselle melkoinen homma. NLP:n avulla tähänkin tekstiaineistoon päästiin pureutumaan kattavasti. Noin 25 tuhatta Trumpin twiittiä hänen presidenttikautensa ajalta analysoitiin ja niistä etsittiin toistuvia puheenaiheita. Tässäkin hankkeessa käytettiin aihemallinnusta, ja mallin ryhmittelemät aiheet otsikoitiin koskemaan esimerkiksi koronaa, vaaleja tai Joe Bidenia.
Trumpin twiittien aiheita ja niiden esiintyvyyttä tarkasteltiin aikajanalla ja vertailtiin muihin tapahtumiin tuona aikana, kuten epidemian leviämiseen tai vaaleihin. Aiheiden osuuksia voi analysoida eri tavoin, sillä malli voi osoittaa yhdelle twiitille useamman eri aiheen painoarvoineen. Esimerkiksi monet Joe Bidenia koskevat twiitit päätyivät myös vaalit-aiheen alle.
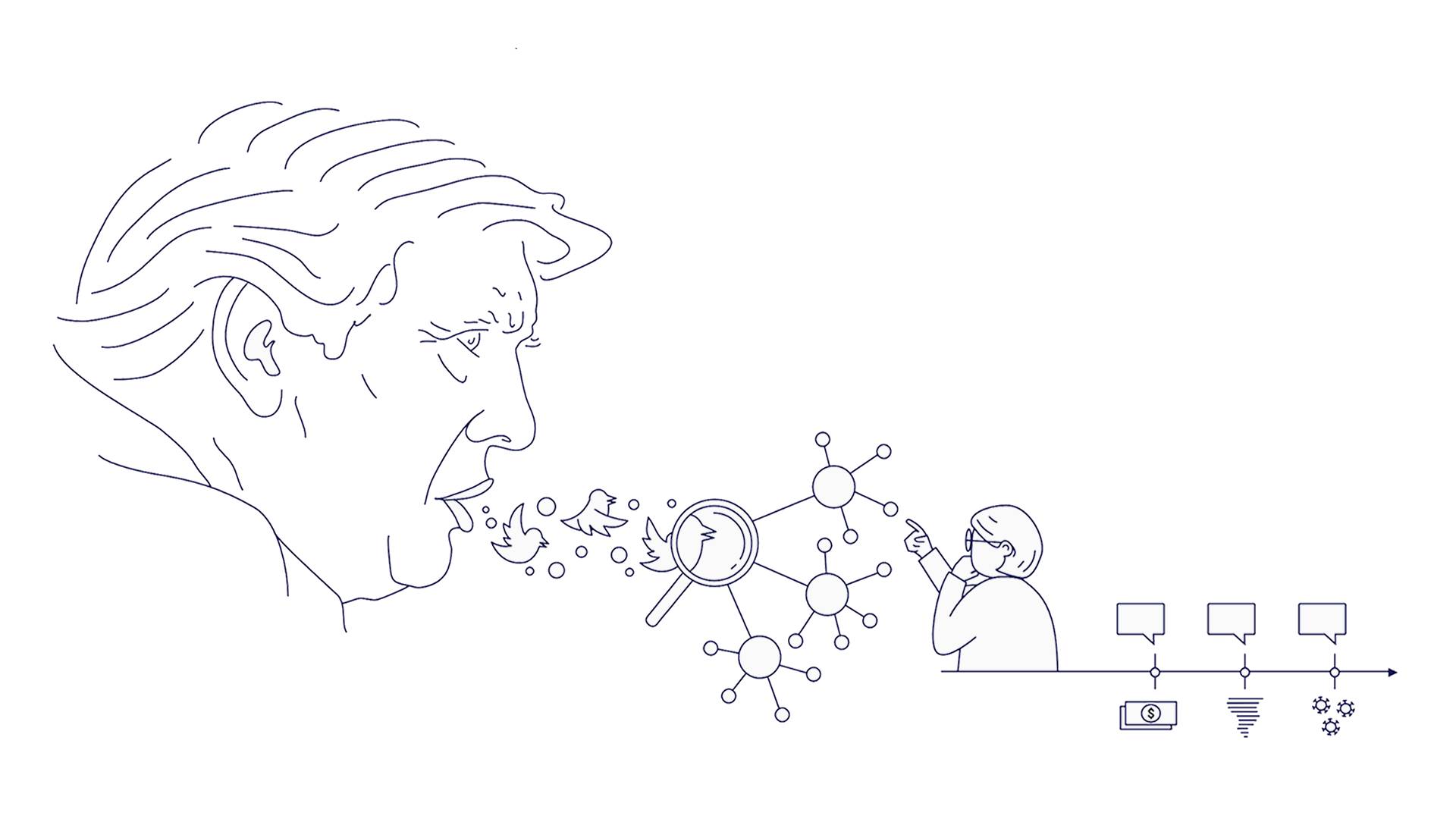
Koneellinen aihemallinnus on paitsi nopeampaa kuin ihmisen tekemä, myös monessa mielessä objektiivisempaa. Vaikka aineisto itsessään saattaa olla vahvastikin painottunut esimerkiksi poliittisen suuntautumisen mukaan, myös ihmis-luokittelijan poliittinen kanta vaikuttaa helposti lopputulokseen. Koneellinen luokittelu ei valitse puolia ideologisista syistä, koska koneoppimismallilla ei lähtökohtaisesti ole ideologiaa.
Aihemallinnuksen avulla voidaan analysoida myös monikielistä aineistoa helposti. Lisäksi sen avulla voidaan lisätä aineistoon asiasanoja eli tageja automaattisesti, ja siten tehostaa isojen aineistojen hakuominaisuuksia.
NLP-menetelmiä voi hyödyntää laajasti kaikkialla missä esiintyy luonnollista kieltäkin, kuten esimerkiksi:
- Uutisten automaattiseen generointiin
- Vihapuheen tunnistamiseen
- Ääniohjaukseen puhetta tunnistamalla
- Chatbotteihin
- Kuvien generoimiseen kuvatekstin avulla
Jos haluat valjastaa tekstimuotoisen datan käyttöösi, lukea tuhat raporttia minuutissa, tai kuulla lisää NLP-menetelmien mahdollisuuksista, niin tavoitat meidät osoitteesta hello@emblica.fi
Emblica ei ole se tavallinen datatiimi. Rakennamme räätälöityjä ratkaisuja datan keräämiseen, käsittelyyn ja hyödyntämiseen alalle kuin alalle, etenkin R&D:n rajapinnassa. Oli kohteemme tehdaslinjasto, verkkokauppa tai pelto, löydät meidät työn touhusta, kädet savessa - ainakin toimistoltamme Helsingistä.