


Lyhyesti suomeksi: Millaisia näkymiä konenäkömenetelmät tarjoavat yhdistettynä reaaliaikaiseen videoon? Yhdistimme kasvojentunnistusmallin Linnanjuhlien lähetykseen, ja kerromme nyt mitä hyötyjä ja huolia näiden menetelmien käyttämiseen liittyy.
What if we had extra eyes?
Imagine watching a video stream with a task to analyze different objects appearing in the image. Perhaps you are interested in recognizing anomalies in the products made in your factory. Or you might be interested in how many animals visit your summer house’s porch. On top of that, you must keep an eye out for anything unusual. It seems quite a lot for one pair of eyes to keep on track, doesn’t it?
Now imagine having “extra eyes” that can spot the individual objects and their characteristics, such as shape or material from every video frame, without ever getting tired. You could set the camera to film 24 hours per day and ask the helping eyes to report all the needed metrics to you in real time.
Watching Linnanjuhlat with a twist
Those extra eyes refer, of course, to Computer Vision (CV) methods. We used a few of those methods in our experiment with the broadcast of Finland’s Independence Day reception (Linnanjuhlat) on the sixth of December. With open-source face recognition models and our pipeline for reading and processing the video in real time, we could watch Linnanjuhlat with updating statistics of the screen times, age and gender distributions, as well as facial expressions of the guests. In addition, we compiled a post-analysis from the data collected during the broadcast.
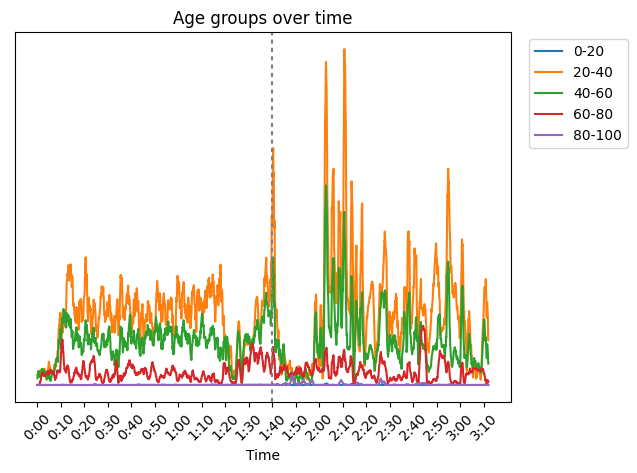
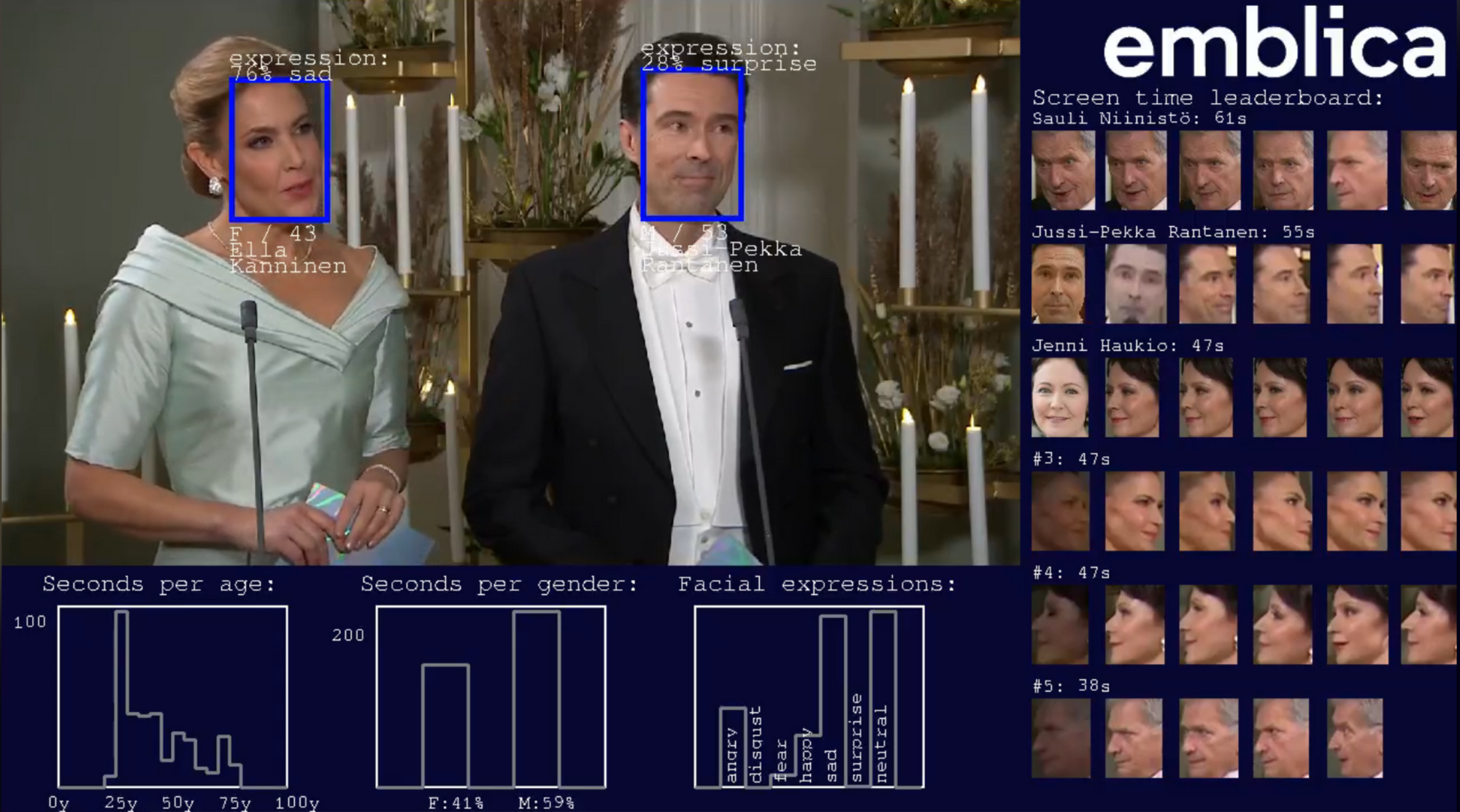
We used existing CV models, namely InsightFace for face recognition, age and gender predictions, and FER for predicting facial expressions. The purpose was to demonstrate the possibilities of these openly available CV models and concretely show their biases. We also wanted to combine different analysis and visualization methods and gather our findings into this blog post you’re reading. And last but not least, this gave us an excellent reason to have a fun time together watching Linnanjuhlat at the office!
Ethics of face recognition
Now the guests in Linnanjuhlat are not products in a factory, nor animals on your porch; they are human beings. When people are involved, there are always ethical concerns in using CV methods, especially face recognition. It is not legally and ethically right to set cameras to film just any event or place, let alone do face recognition or other analysis of it. People have a right to their privacy, even if the content captured by the camera is not saved. Luckily, there are also privacy-preserving options for collecting insights about events or places where people are involved; see our post about point cloud data here!
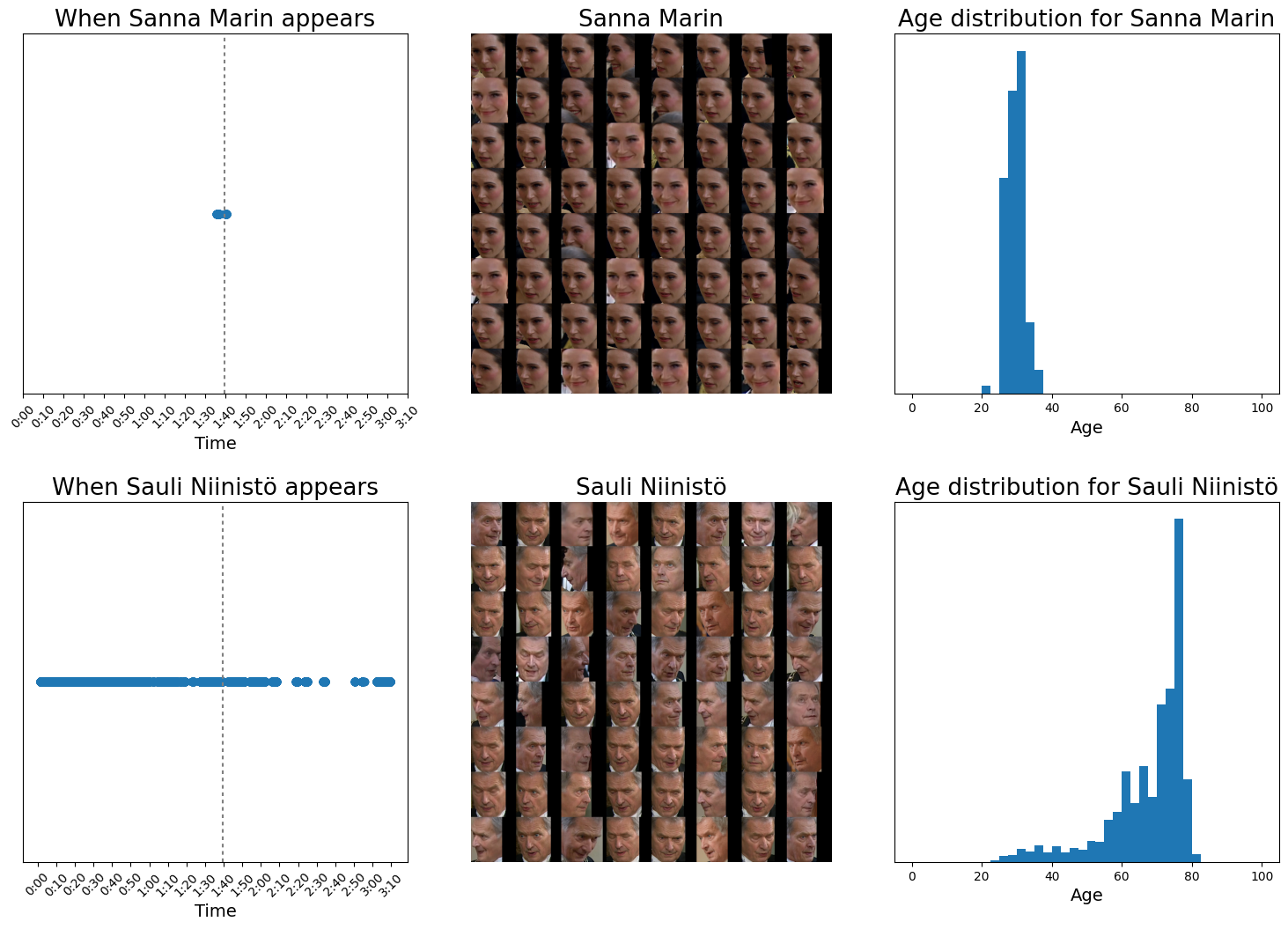
On top of the privacy concern, when using machine learning models such as face recognition, we must always remember that the models are never perfect in all their predictions. For example, our 74-year-old President got a wide range of different age predictions in our experiment, as you can see from the image below. In addition, the data used to teach face recognition models such as InsightFace almost certainly contains bias against some groups of people. This means that the age and gender predictions are more accurate for over-represented groups (white, male) than for some underrepresented groups, not to mention non-binary genders, which was not even an option in the model outputs.
There are also concerns regarding using models that recognize facial expressions. Those expressions should not be confused with the person’s emotions, personality or other interior states or affects. It’s hard enough even for a human to interpret other people’s feelings, so let’s not conclude them based on a machine learning model. For these reasons, CV models that recognize people’s faces or their characteristics should not be used to make important decisions about people.
Main takeaways
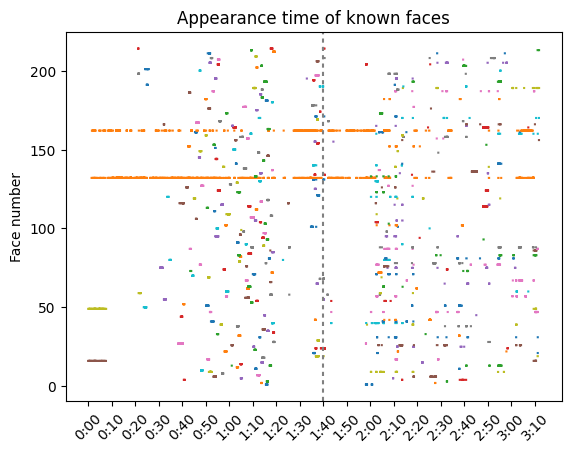
The primary purpose of our experiment was to build a CV system to process real-time video, which required building a video processing pipeline and the CV system on top of it. As a side product, we had a chance to watch Linnanjuhlat with an extra layer: we collected images of Parliament members’ faces beforehand, so our system could show the names of many guests even before the host mentioned them. Our system also showed the screen time leaderboard, from which we saw how many seconds each person had appeared on the broadcast.
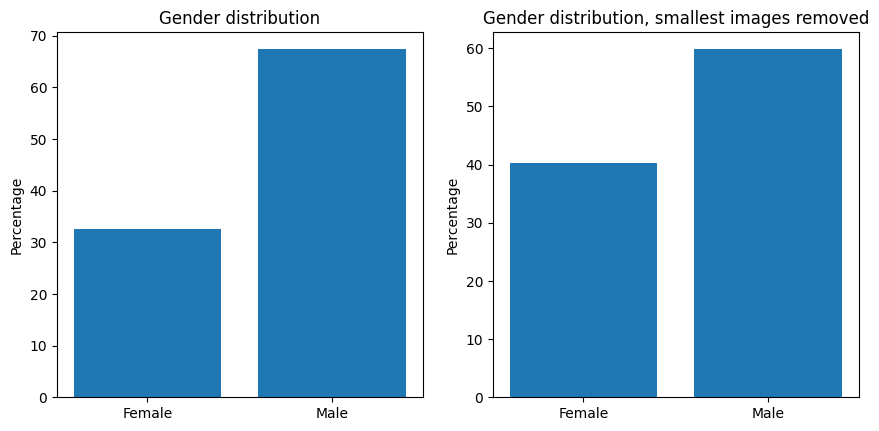
When we watched the guests of Linnanjuhlat shaking hands with the presidential couple, we noticed that distant faces were mostly labeled as males, no matter what their expressed gender was. Most likely, the model has been trained with an unbalanced dataset of more male faces than female faces. Because of this, it is likely more confident to predict blurry and small images as males. When we looked at the gender distribution of faces that were at least 100 pixels high, the gender distribution became more even, supporting this theory.
Watching the live broadcast made it pretty easy to spot these biases and situations when the model predictions were inaccurate. However, in many face recognition applications, even trained humans cannot spot biased outputs as easily. This bias can lead to various problems, anything from Instagram filters not working correctly for people of color to unequal convictions.
In addition to exploring the limitations and possibilities of CV models, building the pipeline was a fantastic project. The technical details of the video, such as frame rate and quality, and the desired result determine how much computing power is needed for real-time CV analysis. We used various open-source libraries and tools for image processing, stream handling and deploying the pipeline. Similar real-time computer vision pipelines can be customized for multiple environments to observe objects like animals, products or vehicles instead of the president's Independence Day guests.
Possibilities
Real-time video stream analysis creates new possibilities for various fields. We can extract structured data from an unstructured mess using simple, robust, and isolated components. Combining data extraction with multiple layers of processing, we can enable something valuable that would be otherwise impossible to implement.
Although this experiment focused on face recognition, the system could also be generalized to recognize other objects. For example, in factory quality assurance, we could teach the system what a good product looks like. Then, during manufacturing, the system would detect and group every product based on how they differ from the good, expected outcome. When a product doesn’t match the predefined “good case” vectors, it will be grouped with others that are faulty in the same way and highlighted for an extra inspection.
This blog is about one part of the computer vision methods we at Emblica are passionate about. Do you have a problem in mind to solve with computer vision methods? We can help you to create a new data stream or product or improve your existing processes. Or do you have a problem you are sure we cannot solve? We would love to hear from it.
Emblica is not your average data team. We build customized solutions for collecting, processing, and utilizing data for all sectors, especially at the R&D interface. Whether our target is a factory line, an online store, or a field, you can find us busy at work, hands in the clay - at least at our office in Helsinki.