
Viimeisen neljän vuoden aikana mediassa on ollut paljon puhetta siitä, miten Trump käyttää sosiaalista mediaa, erityisesti Twitteriä. Aiheesta on kirjoitettu paljon eri medioissa (Nature 2020, NBC News 2020, NYT 2019, Gallup 2018, Politico 2018), mutta suurin osa jutuista keskittyy siihen miksi Trump tviittaa (Nature, Politico, NBC) tai miten hän tviittaa (hyökkäyksiä henkilöitä ja organisaatioita kohtaan, itsensä kehumista, NYT).
Suomen Kuvalehti kirjoittaa tuoreessa artikkelissaan, miten Trump johti Yhdysvaltoja presidenttikautensa aikana Twitterissä. Osaksi juttua haluttiin ymmärrys siitä, mistä puheenaiheista Trump on kautensa aikana tviitannut. Tämä on näkökulma, joka on laajasti sivuutettu aikaisemmissa kirjoituksissa.
Miksi puheenaiheita kannattaa etsiä tekoälyn avulla?
Yksi syy puheenaiheiden sivuuttamiselle aikaisemmissa uutisartikkeleissa on, että aiheiden tunnistaminen tekstistä on erittäin vaikeaa tehdä objektiivisesti. Ihmisen elämänkokemus ja mielipiteet vaikuttavat merkittävästi siihen, millaisiin asioihin kiinnitämme huomiota (ennakoiva prosessointi, predictive processing). Esimerkiksi lukijan poliittinen suuntautuminen vaikuttaa todella paljon siihen, mihin hän kiinnittää huomiota Trumpin tviiteissä, ja sitä myöten myös puheenaiheen tulkinta värittyy.
Toinen syy Trumpin puheenaiheiden vähäiselle analyysille on aineiston suuri määrä. Pystyisitkö sinä lukemaan 25 000 tviittiä ja kertomaan luotettavasti, mitä mitä yhtä usein käsiteltyjä puheenaiheita tviiteissä on esiintynyt? Emme pystyneet mekään, joten koulutimme tekoälyn tekemään alustavan aiheanalyysin puolestamme.
Miksi puhumme “tekoälystä”?
Tekoäly (artificial intelligence) on järjestelmän ominaisuus samalla tavalla kuin äly on ihmisen, apinan, tai vaikkapa sian ominaisuus. Koska puheenaiheiden tunnistaminen tekstistä vaatii älykkyyttä, eikä tekemämme järjestelmä ei ole biologinen olento, on kyseessä tekoälyjärjestelmä (AI system).
Järjestelmän toteutuksesta puhuttaessa ei kuitenkaan ole syytä puhua tekoälystä. Samalla tavalla, kuin aivojen yksittäiset neuronit eivät ole älykkäitä, tekoälyjärjestelmän toteutuspalikat eivät ole (teko)älykkäitä. Niistä puhuttaessa käytetään tarkemmin määriteltyjä termejä kuten “koneoppiminen” tai “algoritmi”.
Mistä data kerättiin?
Trump Twitter Archive on kerännyt vuosien ajan kaikki Trumpin tviitit Twitterin ulkopuoliseen tietokantaan. Kannasta löytyy Trumpin henkilökohtaisen tilin kaikki tviitit ja uudelleentviittaukset, mukaanlukien poistetut tviitit. Aineistoa on käytetty laajasti Trumpin tviittausta koskevissa analyyseissä.
Puheenaiheet tviiteissä
Marraskuussa 2017 Trump tviittasi Pohjois-Korean päämiehestä Kim Jong-unista seuraavasti:

Ihmisen silmin tämä tviitti voisi liittyä esimerkiksi puheenaiheisiin “Pohjois-Korea”, “Kim Jong-un”, “Donald Trump”, “nimittely”, ja “kiusaaminen”. Jos tviittejä tarkastelee yksittäin, erilaisia puheenaiheita voi keksiä lähes loputtomasti. Puheenaiheiden esiintymisen vertailua varten meidän tulee kuitenkin valita rajallinen määrä puheenaiheita, joiden esiintymistä tarkastellaan.
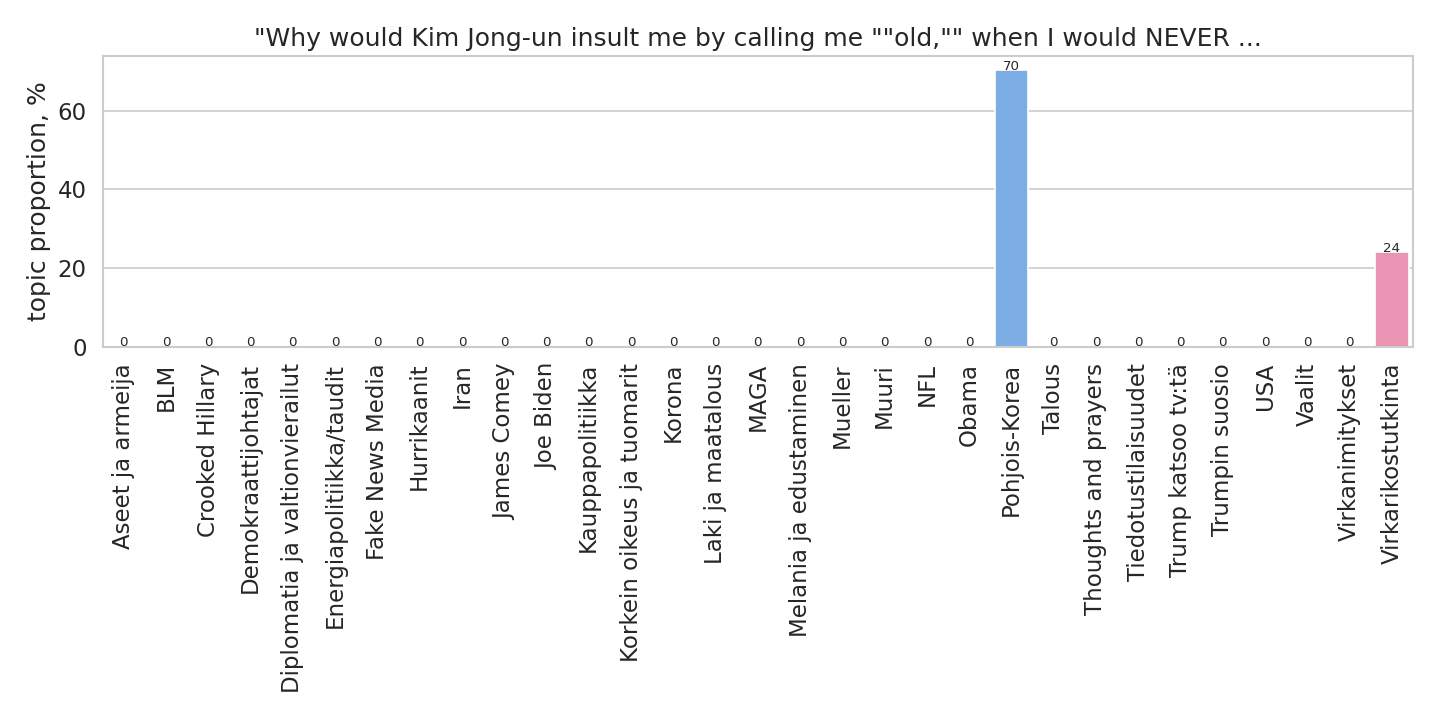
Yllä olevasta kuvaajasta voidaan nähdä, että tekoäly on arvioinut, mistä puheenaiheista aiemmin esitetty esimerkkitviitti koostuu. Kaikista 31:stä mahdollisesta puheenaihesta läsnä on selkeästi kahta eri aihetta, ja suurin aihe on selkeästi Pohjois-Korea. Toisin sanoen, kaikki puheenaiheet ovat läsnä jokaisessa tviitissä ja niiden läsnäolon määrä vaihtelee tviitin sisällön mukaan. Kun selkeästi nollasta poikkeavia aiheita on useampi, voidaan tulkita että tviitti kuuluu useaan eri puheenaiheeseen.
Kuinka puheenaiheiden mallintaminen toteutettiin?
Trumpin tviiteissä esiintyvien puheenaiheiden mallintaminen tehtiin karkeasti ottaen neljässä osassa.
- Aineiston (tviittien) keräys ja esikäsittely,
- Koneoppimismallin kouluttaminen puheenaiheiden tunnistamiseen,
- Puheenaiheiden tarkastaminen ja karsiminen,
- Merkityksellisten puheenaiheiden tarkastelu presidenttikauden ajalta.
Aineiston keräys ja esikäsittely
Jotta Trumpin tviittien sisältöjä voidaan arvioida, pitää tviitit saada ladattua ja esiprosessoitua. Tässä tapauksessa aineiston lataaminen oli helppoa, ja muutaman napin painalluksen jälkeen tviitit olivat tallessa. Tviitit, mallinnustermein “dokumentit”, ovat kuitenkin sotkuisia, eikä niitä pysty saman tien hyödyntämään. Tällä ei tarkoiteta Trumpin kielenkäyttöä, vaan merkityksettömiä sanoja (stop words).
Luonnollisen kielen mallintamisessa aineisto kannattaakin usein esikäsitellä, ja merkityksettömät sanat on hyvä poistaa. Esimerkiksi sana “ja” ei kerro yksinään mitään merkityksellistä lauseessa “Emblica ja Suomen Kuvalehti tekivät yhteistyötä”, vaan sen tuoma merkitys tulee kontekstista. Tämän vuoksi merkityksettömät sanat, kuten “ja”, “ehkä”, “joka”, “mutta”, poistetaan usein osana tekstin esikäsittelyä luonnollisen kielen mallintamisessa.
Toinen tapa tehdä tekstistä helppolukuisempaa koneelle on sanojen muuttaminen samaan kirjoitusasuun esimerkiksi poistamalla sanojen kirjoitusvirheitä ja muuntamalla taivutettuja sanoja perusmuotoon. Esimerkkinä voidaan käyttää vaikkapa tätä alkuperäistä tekstiä:
Why would Kim Jong-un insult me by calling me "old," when I would NEVER call him "short and fat?" Oh well, I try so hard to be his friend - and maybe someday that will happen!
Tviitti muuttuu paljon ytimekkäämmäksi esikäsittelyn myötä:
why would Kim Jong - un insult call old, -PRON- would never call short fat? " " oh well , -PRON- try hard friend - maybe someday happen!
Tällainen yksinkertaistettu teksti on kontrolloidumpaa kuin täysin vapaasti kirjoitettu luonnollinen kieli, ja sen vuoksi sitä on myös helpompi mallintaa.
Kielen yksinkertaistaminen ei kuitenkaan ole tarpeeksi koneelle, koska opetettava malli ei ymmärrä, mitä sanat tarkoittavat. Tietokoneet ymmärtävät loppukädessä vain "ykkösiä ja nollia", joten laskutoimitusten kannalta on otollista esittää teksti vektorina, eli listana numeroita.
Suoraviivainen ja yleisesti käytetty lähestymistapa luonnollisen kielen vektorisointiin on ns. one-hot encoding, jossa teksti muokataan käytettävän sanaston mittaiseksi vektoriksi (esimerkiksi tässä projektissa käytetyssä englannin kielen sanastossa on 29197 sanaa). Yhtä tviittiä kuvaavassa vektorissa on nolla kaikkien sanojen kohdalla, jotka eivät tviittiin sisältyneet. Numero yksi taas löytyy niiden sanojen kohdalta, jotka tviitistä löytyivät. Tästä juontaa juurensa nimi one-hot encoding.
Yllä esitetyn tviitin vektorisoidussa muodossa on 29179 nollaa ja 18 nollasta poikkeavaa arvoa.
Koneoppimismallin kouluttaminen tunnistamaan puheenaiheita
Maailmassa on paljon puheenaiheita, eivätkä ne kaikki esiinny Donald Trumpin tviiteissä. Trumpin tviiteistä on kuitenkin löydettävissä paljon toistuvia teemoja, esimerkiksi markkinoihin sekä kauppapolitiikkaan liittyvää sanastoa, kuten “market”, “billion”, “stock” ja “trade”. Näiden usein yhdessä esiintyvien sanojen voidaan ajatella liittyvän puheenaiheeseen “Talous”. Nykyaikaiset koneoppimismallit eivät varsinaisesti ymmärrä mitä sanat tarkoittavat, mutta ne pystyvät löytämään sanojen esiintymisen perusteella aiheryhmiä joihin sanat liittyvät.
Yksi tällainen puheenaiheita oppiva koneoppimismalli on Latent Dirichlet Allocation (LDA). Mallin kouluttaminen vaatii kasan dokumentteja (tässä tapauksessa esiprosessoidut tviitit) ja parametrin, joka määrittää kuinka moneen puheenaiheeseen aineisto pitäisi pystyä jakamaan. Tässä analyysissä puheenaiheiden määräksi valittiin 50 useiden kokeiluiden jälkeen.
Malli koittaa selittää jokaisen tviitin sisällön, toisin sanoen tviitin sanat, puheenaiheiden avulla. Lukemalla suuren määrän tviittejä malli saa käsityksen, mitkä sanat esiintyvät yhdessä, eli mitkä sanat liittyvät samaan puheenaiheeseen. Koulutusvaiheessa LDA käy läpi koko aineiston (tässä tapauksessa kaikki tviitit) useaan kertaan. Jokaisen läpikäynnin jälkeen LDA optimoi parametrejaan siten, että puheenaiheet ovat mahdollisimman selkeitä ja koherentteja eri tviittien välillä.
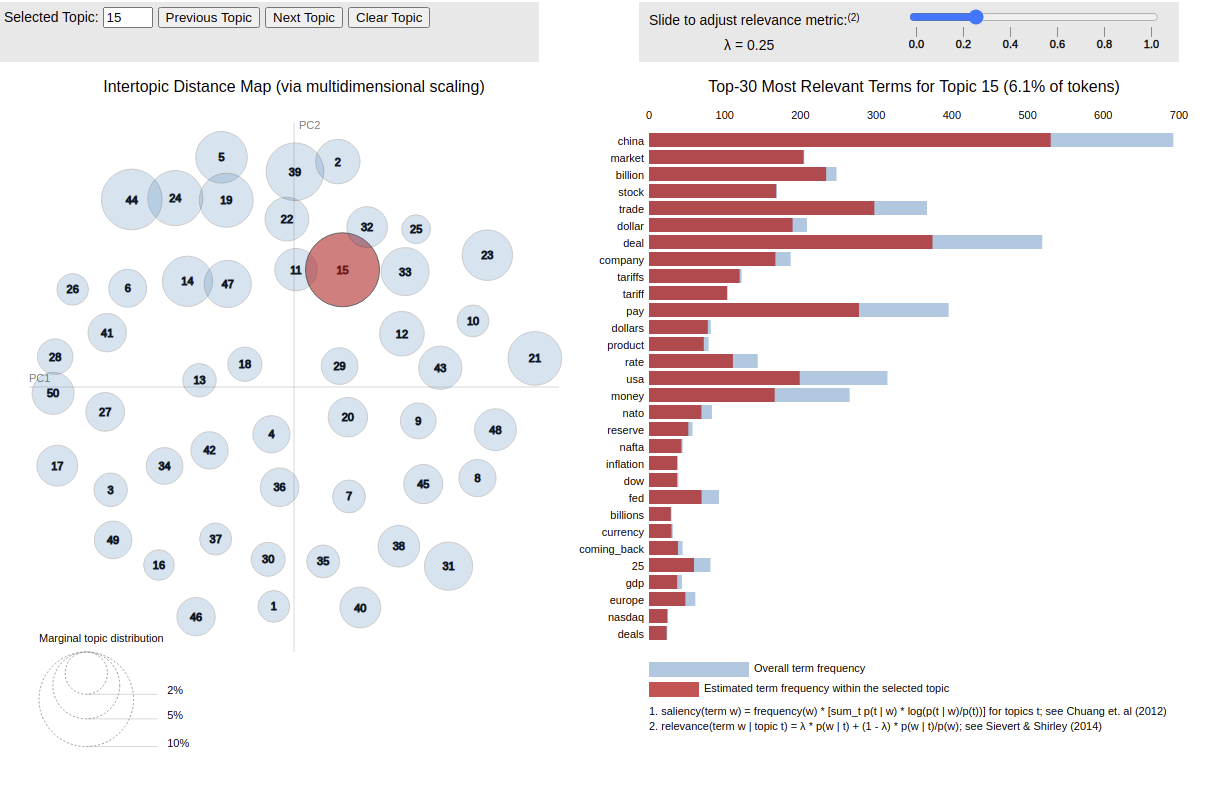
Kun koulutus onnistuu hyvin, merkitykselliset sanat kuten “North Korea”, “law”, ja “dollar” eriytyvät omiin aiheisiinsa. Samalla myös yleisesti käytetyt sanat kuten “good”, “make”, ja “great”, jakautuvat usean eri aiheen välille.
Koska LDA ei ymmärrä sanojen merkityksistä yhtään mitään, se ei osaa kertoa mikä kunkin puheenaiheen otsikko tulisi olla. Se ei myöskään osaa arvioida, mitkä puheenaiheet ovat yhdenmukaisia (esim. aiheeseen vahvasti liittyvät sanat liittyvät kaikki Pohjois-Koreaan) ja mitkä aiheet ovat sekalaisia (esim. samaan aiheeseen liittyvät sekä “commerce”, “spying”, että “fully support”). Sen takia puheenaiheiden nimeämiseen ja tarkastamiseen tarvitaan lukutaitoista ihmistä.
Puheenaiheiden tarkastaminen ja karsiminen
Lukutaitoisia ihmisiä oli onneksi käytettävissä, kun tämän LDA:n koulutus oli valmis. Kaikki 50 aihetta käytiin läpi tarpeeseen suunnitellulla työkalulla. Puheenaiheisiin liittyvien termien perusteella yhdenmukaiset puheenaiheet nimettiin, ja sekalaiset, epäkoherentit puheenaiheet karsittiin pois. Jäljelle jäi 31 puheenaihetta.
Aineiston esikäsittely ja koneoppimismallin kouluttaminen eivät LDA:n tapauksessa kärsi ihmisten ennakkokäsityksistä. Mallille ei kerrottu mitään puheenaiheista, joita aineistosta tulisi löytää, mutta sille annettiin etsittävien puheenaiheiden määrä. Tämän takia LDA:n löytämiä teemoja voidaan pitää tietyssä mielessä objektiivisina tai “puolueettomina”.
Puheenaiheiden nimeäminen vaatii ihmisten mielipidettä ja valvontaa, ja sen vuoksi siihen sisältyy väkisinkin subjektiivisuutta. Koska puheenaiheiden nimeämisessä ei ole absoluuttisen oikeita tai vääriä vastauksia, jää nimeäjälle mahdollisuus otsikoida aiheet positiiviseen tai negatiiviseen sävyyn.
Hyvin eriytyneet aiheet on kuitenkin usein helppoa nimetä. Esimerkiksi alla olevassa kuvaajassa on esitetty aiheen nro 47 tärkeimmät termit, joiden otsikointi on varsin yksioikoista kansainvälistä politiikkaa tuntevalle ihmiselle.
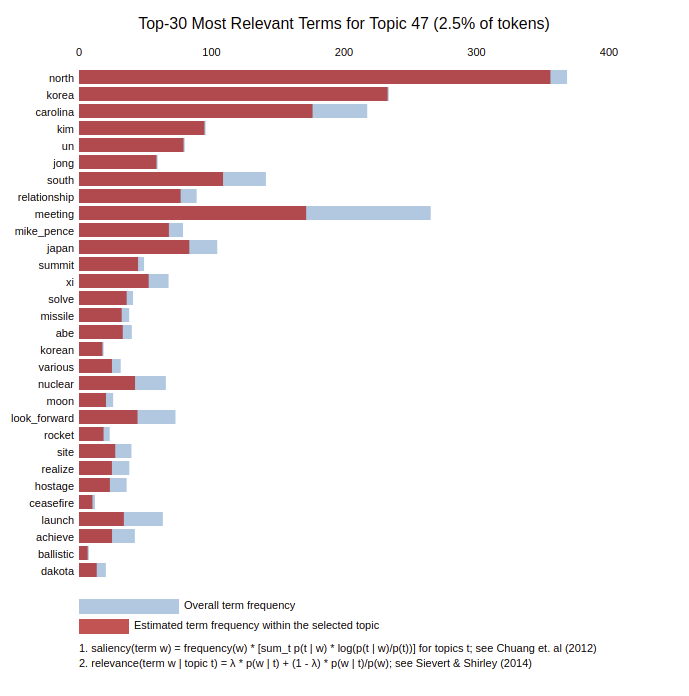
Jos LDA:n löytämä aihe ei ole selkeä, sen voi karsia pois sekoittamasta analyysejä. Viidestäkymmenestä LDA:n löytämästä aiheesta 19 oli niin sekalaisia, että Suomen Kuvalehden toimittajat päättivät jättää ne analyyseistä pois. Tämä karsimisoperaatio ei ole välttämätön puheenaiheita mallinnettaessa, mutta tässä tapauksessa haluttiin varmistua siitä, että puheenaiheet ovat selkeitä ja hyvin määriteltyjä, jotta myöhemmin tehtävät analyysit ovat luotettavampia. Tämä on myös journalistisesti ajatellen tärkeää, koska lopullinen vastuu tulkinnoissa jää aina toimitukselle. Hyvin tehtyä analyysia on tulee olla turvallista tulkita.
Merkityksellisten puheenaiheiden tarkastelu presidenttikauden yli
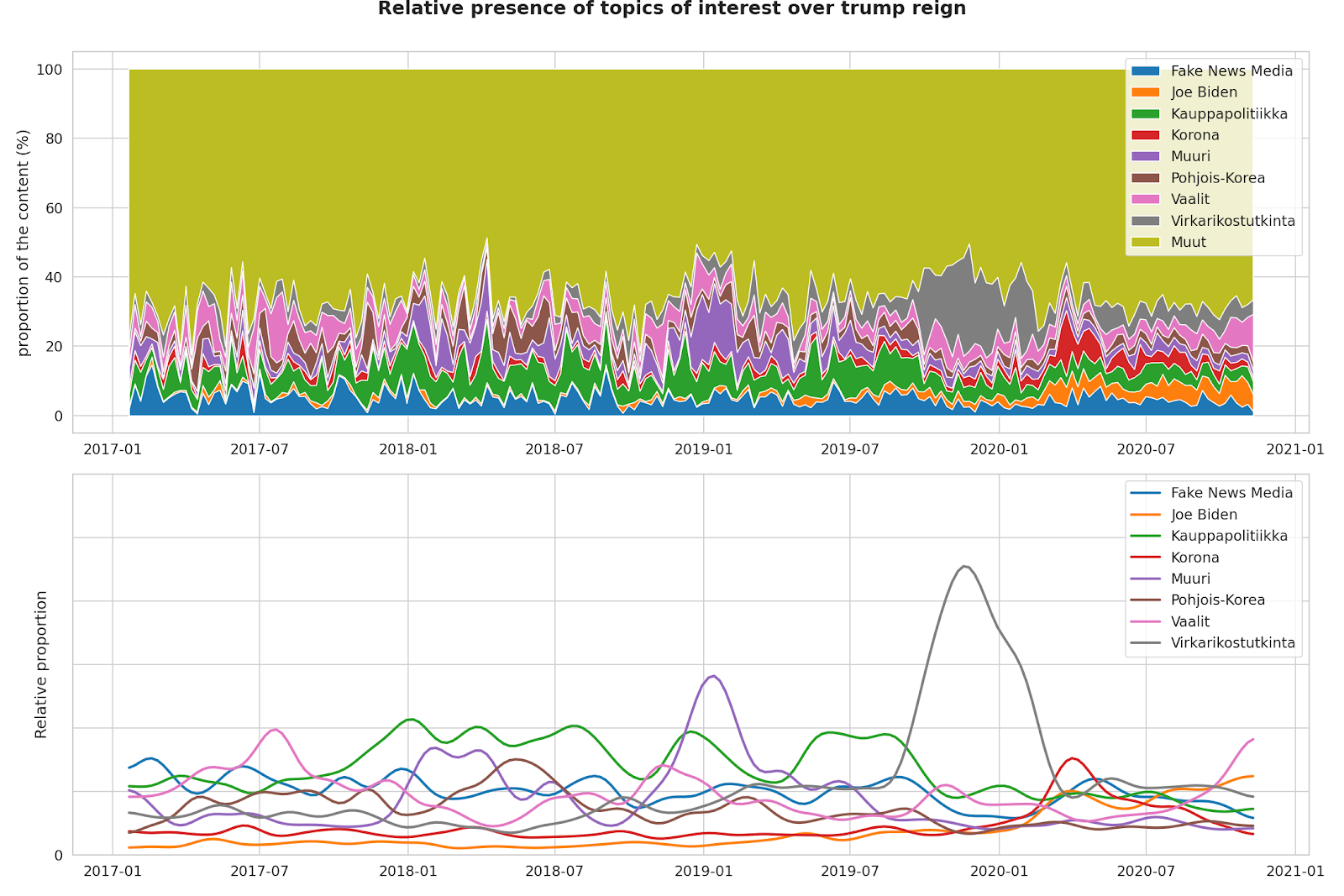
Sen jälkeen, kun puheenaiheet on karsittu ja nimetty, niiden esiintymistä voidaan tarkastella ajan yli. Alla olevassa kuvaajassa on esitetty kuuden puheenaiheen suhteellinen osuus Trumpin tviittaamasta sisällöstä hänen presidenttikautensa ajalta.
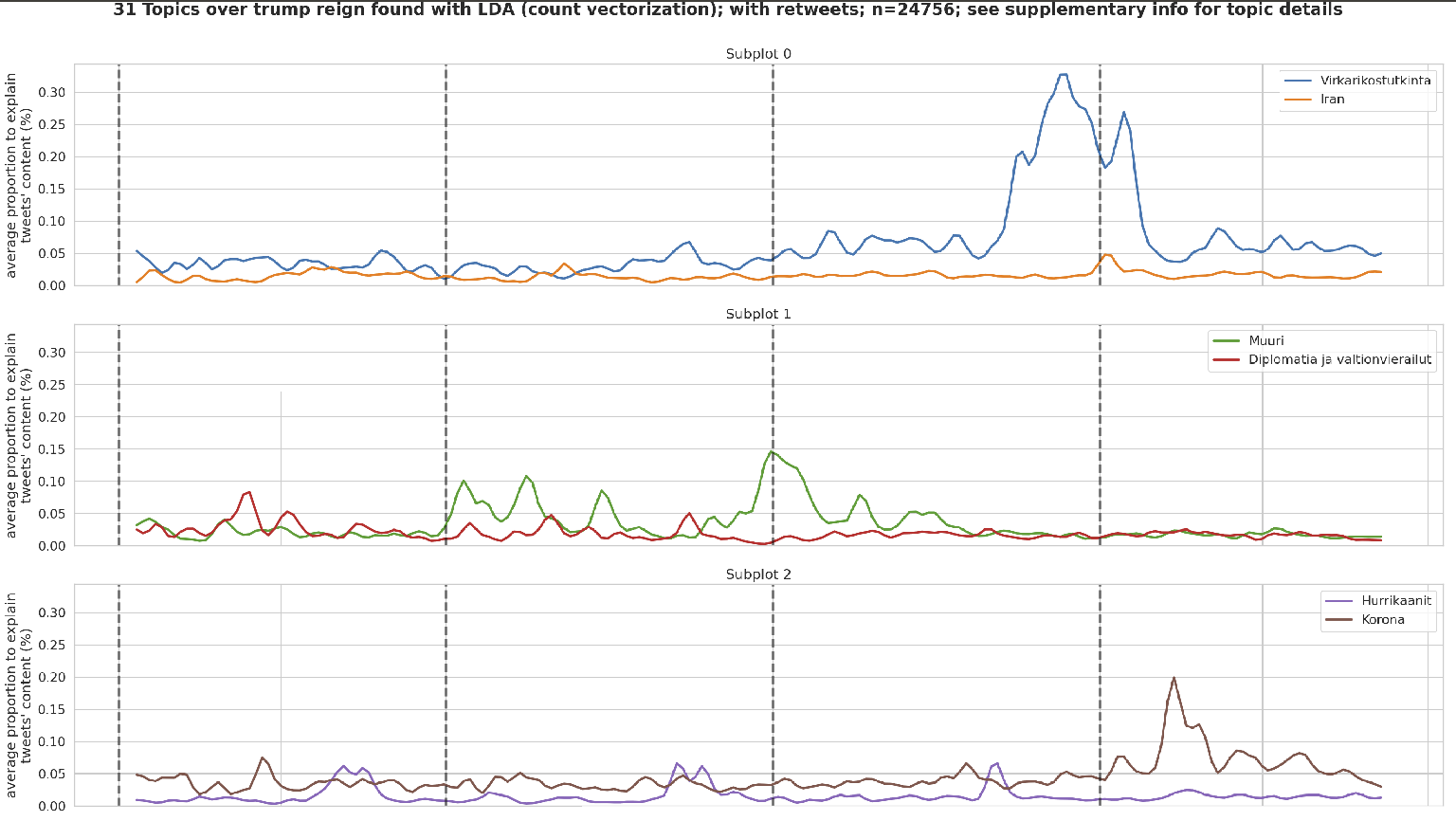
Yksittäisten aiheiden korostuminen tiettyinä aikoina oli Suomen Kuvalehdelle hyvä tapa varmistaa, että tulkinnat puheenaiheista pitivät paikkansa. Esimerkiksi Hurrikaanit -aiheen painotus osuu Pohjois-Amerikan hurrikaanikaudelle, mikä oli odotettua. Myös Korona -aihe on eniten esillä vuoden 2020 ensimmäisellä puoliskolla, kun Covid-19 saapui rytinällä Yhdysvaltoihin.
Toinen tapa arvioida puheenaiheiden nimeämisen onnistumista on lukea tviittejä, joiden sisältö on LDA:n mukaan johtunut melkein yksinomaan yhdestä aiheesta. Esimerkiksi seuraava tviitti koostuu LDA:n mukaan 97.6% puheenaiheesta, jonka toimittajat nimesivät “Fake News Media” -aiheeksi:
NBC FAKE NEWS, which is under intense scrutiny over their killing the Harvey Weinstein story, is now fumbling around making excuses for their probably highly unethical conduct. I have long criticized NBC and their journalistic standards-worse than even CNN. Look at their license?
(2019-08-24 15:00:34)
Tviitit puheenaiheissa
Kun kaikki tviitit luokitellaan kuuluvaksi siihen puheenaiheeseen, joka oli eniten läsnä tviitissä, Trumpin tviitit presidenttikauden ajalta jakautuvat järjestelmän löytämiin puheenaiheisiin seuraavasti:

Kuvaaja sisältää kuitenkin myös kaikki sellaiset tviitit, joissa kaikki puheenaiheet ovat tasavahvoja, eikä tviitti kuulu erityisemmin mihinkään puheenaiheeseen. Esimerkiksi seuraava tviitti saa järjestelmältä varsin tasavahvat pisteet kaikkiin puheenaiheisiin:
Daniel Cameron, who just won the A.G. race in the Great Commonwealth of Kentucky, is a young and very talented political star. You will be hearing much from Cameron in the yesrs to come!
(2019-11-23 05:02:12)
Saa järjestelmältä varsin tasavahvat pisteet kaikkiin puheenaiheisiin:

Yllä oleva tviitti oltaisiin luokiteltu lopulta puheenaiheeseen virkarikostutkinta, vaikka muut puheenaiheet ovat yhtä vahvoja. Tämän vuoksi on hyvä edellyttää, että puheenaihe on tarpeeksi vahva, esimerkiksi 33%, jotta tviitti voidaan laskea kuuluvaksi kyseiseen puheenaiheeseen. Kun puheenaiheilta vaaditaan minimissään kolmasosan läsnäoloa, Trumpin tviitit jakautuvat puheenaiheisiin seuraavasti:

Tällä tavalla laskettuna jokainen tviitti kuuluu 0-3:een puheenaiheeseen, useimmiten kuitenkin vain yhteen puheenaiheeseen.
Mallinnuksen vahvuudet ja heikkoudet
Puheenaiheiden mallinnukseen on useita erilaisia lähestymistapoja, mutta suuressa osassa niistä on vaikea välttää ihmiskäyttäjästä tai valitusta koulutusaineistosta johtuvan harhan (bias) opettamista koneoppimismallille. LDA on laajasti käytetty ja tutkittu työkalu puheenaiheiden mallintamiseen, ja sen vahvuutena on sen objektiivisuus: mallille ei kerrota etsittävistä puheenaiheista mitään muuta, kuin niiden lukumäärä. Tämän ansioista mallin kouluttajan maailmankuva ei vaikuta siihen, millaisia puheenaiheita LDA löytää.
LDA:n koulutus onnistuu valvomatta (unsuperviced learning), mikä tekee siitä erittäin vaivatonta ja kustannustehokasta. Monet tekstin luokitteluun perustuvat aihe-mallit vaativat luokitellun koulutusaineiston, jonka koostaminen on usein työlästä ja kallista.
Sen sijaan sopivan aiheiden lukumäärän valitseminen on tärkeä osa onnistunutta koulutusta. Jos puheenaiheita etsitään liian vähän (tässä tapauksessa esimerkiksi 10), yhdistelee malli toisiinsa liittymättömiä puheenaiheita saman aiheen alle. Jos tätä ei huomata ja puheenaiheet otsikoidaan nopean läpikäynnin jälkeen, voi aiheen sisältö olla todellisuudessa jotain aivan muuta kuin mitä keskeisimmät termit antavat ymmärtää. Jos aiheita taas etsitään liian suuri määrä, silloin isot puheenaiheet (tässä analyysissä esimerkiksi Virkarikostutkinta, Joe Biden, ja Fake News Media) voivat pilkkoontua pienemmiksi ja kokonaiskuva vinoutuu.
LDA:n heikkoudet
LDA:lla on myös heikkoutensa. Koska aineisto vaikuttaa suuresti sopivaan puheenaiheiden määrän sitä ei voi tietää etukäteen. Hyvän määrän löytäminen vaatii usein monta kierrosta koulutuksia ja aiheiden läpikäyntejä. Tämä vaatii mallin kouluttajalta ja tarkastajalta jonkin verran luku- ja ajattelutyötä. Lisäksi dokumenttien, tässä tapauksessa tviittien, sisältö, pituus, ja tyyli vaikuttavat siihen, kuinka helppo niistä on löytää puheenaiheita. Tviitit ovat tunnetusti hankalia mallinnettavia, koska ne ovat niin lyhyitä. Toinen samaan aikaan vaikuttava ongelma on LDA:n naiivius. Malli ei suoranaisesti ota kantaa miten sanoja on käytetty, vaan sanojen ilmeneminen on selittävä tekijä. Aikaisemmassa tutkimuksessa on kuitenkin havaittu tällä menetelmällä saatavan hyviä tuloksia myös monimutkaisempiin malleihin verrattuna.
Yleinen haaste puheenaiheiden mallintamisessa on aiheiden esiintyminen analyysissä ennen sitä, kun ne ovat olleet oikeasti olemassa. Esimerkiksi puheenaihe Korona on mallin mielestä ollut läsnä jo vuonna 2017, paikoitellen jopa 5% Trumpin viikottaisten tviittien sisällöstä. Onko kyse siitä, että fiksu tekoäly ymmärtää Covid viruksia olleen joka vuosi (ja sen vuoksi vallitsevan pandemian aiheuttaja on nimeltään Covid-19, koska se puhkesi Kiinassa vuonna 2019)? Ei suinkaan. Trump on käyttänyt tviiteissään samoja sanoja vuonna 2017, jotka tekoäly yhdisti tässä analyysissä puheenaiheeseen, jonka myöhemmin tulkittiin edustavan koronavirusta.
Muut mahdolliset mallit
Puheenaiheiden ilmestyminen ja häviäminen on haastava ongelma, jota varten on kehitetty dynaamisia aihe-malleja (esim. Dynamic Topic Models). Joissain käyttötapauksissa nämä mallit toimivat paremmin kuin tavallinen LDA, mutta myös niillä on omat rajoituksensa. Esimerkiksi tässä projektissa dynaamiset mallit eivät pärjänneet lyhyiden tviittien kanssa.
Hienostuneemmissa ja monimutkaisemmissa malleissa saatetaan ottaa myös kontekstia huomioon, esimerkiksi sanajoukot “en syö kalaa” ja “pidän kalasta” saattavat liittyä samaan aihepiiriin, mutta ovat näkemyksiltään täysin vastakkaisia. Näiden mallien kohdalla hyödyntämispotentiaalia laskee kuitenkin niiden selitettävyys (kuinka selvitämme miksi malli on luokitellut tviitin johonkin tiettyyn aiheeseen) ja useissa tapauksissa vaatimus esimerkkidatasta koulutusta varten. Täydellistä ratkaisua ei siis toistaiseksi ole keksitty, ja siksi aihemallinnus onkin edelleen erittäin tutkittu ja tärkeä aihe luonnollisen kielen mallintamisessa.
Kiinnostuitko aiheesta?
Jos tekoäly, koneoppiminen, niiden erot askarruttavat, käy tutustumassa Kill the AI-koulutukseen.
Emblica ei ole se tavallinen datatiimi. Rakennamme räätälöityjä ratkaisuja datan keräämiseen, käsittelyyn ja hyödyntämiseen alalle kuin alalle, etenkin R&D:n rajapinnassa. Oli kohteemme tehdaslinjasto, verkkokauppa tai pelto, löydät meidät työn touhusta, kädet savessa.