



Lyhyesti suomeksi: Onko datasettisi liian pieni? Onko kallista tai jopa mahdotonta kerätä lisää dataa? Eikö yksinkertainen datasettisi kuvaa todellista maailmaa tarpeeksi hyvin? Oletko yrittänyt... täydentää dataasi?
In an earlier blog post, we discussed how we used data augmentation to create more data for the Finnish Environment Institute (Suomen ympäristökeskus, SYKE). There we generated pictures of lake environments and flood meters using the 3D graphics software Blender. This time we take a further look into data augmentation in general.
So what is data augmentation?
Data augmentation is about artificially generating more data for the model training dataset. It is usually needed when there is not enough available data, or the existing data is too monotonous compared to the actual phenomenon we want to predict.
There are two main ways to generate more data: you can modify existing data by adding small variations while still retaining the essence of the original phenomenon. Alternatively, you can produce data from scratch, synthetically. Augmentation can fill in, or enrich the existing dataset, ensuring the model will work in all real-world situations.


In this blog post we will take a deeper look into this topic:
- When is data augmentation needed?
- When is data augmentation possible?
- What tools do we have for data augmentation?
So let's get into it:
When is data augmentation needed?
Data augmentation is needed when the existing data is simply not enough or is too one-sided compared to the environment it needs to be working in.
Let's imagine you are working on a voice interface for your application but only have access to one person's voice to train your models. Without more varied training data your application will probably only work with that specific voice. If your application needs to work for more than one user and you cannot get everyone to submit their voice to the training dataset, you need data augmentation.
By artificially changing the pitch, pace, tone, and volume of your training data, you can create more examples to make your model more robust for different types of voices. It might also be good to introduce some background noise to the recordings to ensure that your interface still works in a noisy environment.
The need for better data can be often seen at the latest when the model overfits (when a model works well with the training data, but not with real-world examples outside of the training data). With experienced data scientists and discussions with domain experts, the risk of overfitting can be recognized even before the work has started. One way to solve this problem is to use data augmentation to enhance your training dataset.
When is data augmentation possible, and how to do it?
In the most basic form, data augmentation is practically always possible. Images can be rotated and flipped, data can be cropped from different regions, and noise can be added to sound, text, and image data. These simple variations that would naturally occur due to environmental conditions make the model tolerate more varied data examples.
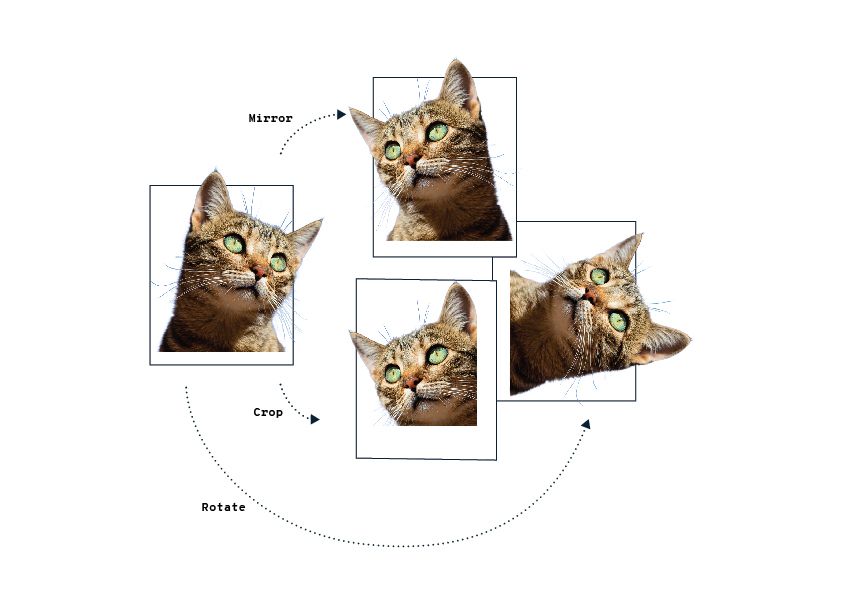
However, domain knowledge becomes necessary when more artificial data is required. If the artificial data does not represent the real world close enough, the model can learn unwanted behavior.
What tools are available?
Let's take a look at a few concrete cases of examples of data augmentation.
Case 1) Generating data for water scale detection
When we were working with The Finnish Environment Institute (SYKE) to automatize data collection in nature, a synthetic dataset was generated for water level prediction. The target for the system was a water scale, which we decorated with special fiducials (round markers on the picture below) to measure the water height.

But there are hundreds of locations around Finland, and we could get the cameras and fiducials running only on a few of them during the project itself, it was out of the question to train the model with actual pictures. Instead, we generated the training dataset ourselves with the aid of Blender!

For the model to identify the scale in all the different locations, with various angles, illumination conditions, levels of corrosion, and occlusion, we had to generate a dataset just as wide and robust. The water scales were generated as 2D images and then inserted into various, watery backgrounds. The pictures were also decorated with different lighting conditions. Finally, sooty filters and cropping were applied over the scales for occlusion.
With this dataset, the model got great results even in the live setups themselves.

Case 2) Generate user feedback via conglomeration
Augmentations that can be done for text are highly dependent on the task at hand: for sentiment prediction, especially with a scheme that does not take into account the order of the words, a random sample of words can be assembled from the existing dataset.
The same cannot be done if maintaining their ordering is necessary for the prediction. But if the data is for short reviews of the same service, it might be possible to concatenate reviews with similar scores.

Here the combination of similarly scored reviews allows the model to associate the different words stronger together, allowing it to average over similar content.
Case 3) Generating realistic user profiles to simulate different customers
Let's say you want to build a recommendation engine that creates personalized recommendations from the eco-friendly products of your eco-friendly e-commerce. You might have very little data from real customers and their purchase history because your business is very new. Tabular data, like your customer information (age, location, preferences, purchase history, etc.), can't be rotated (case 1) nor shouldn't be fully concatenated (case 2). But you can learn trends from your tabular data and generate realistic but unique user profiles to train your recommendation engine with.
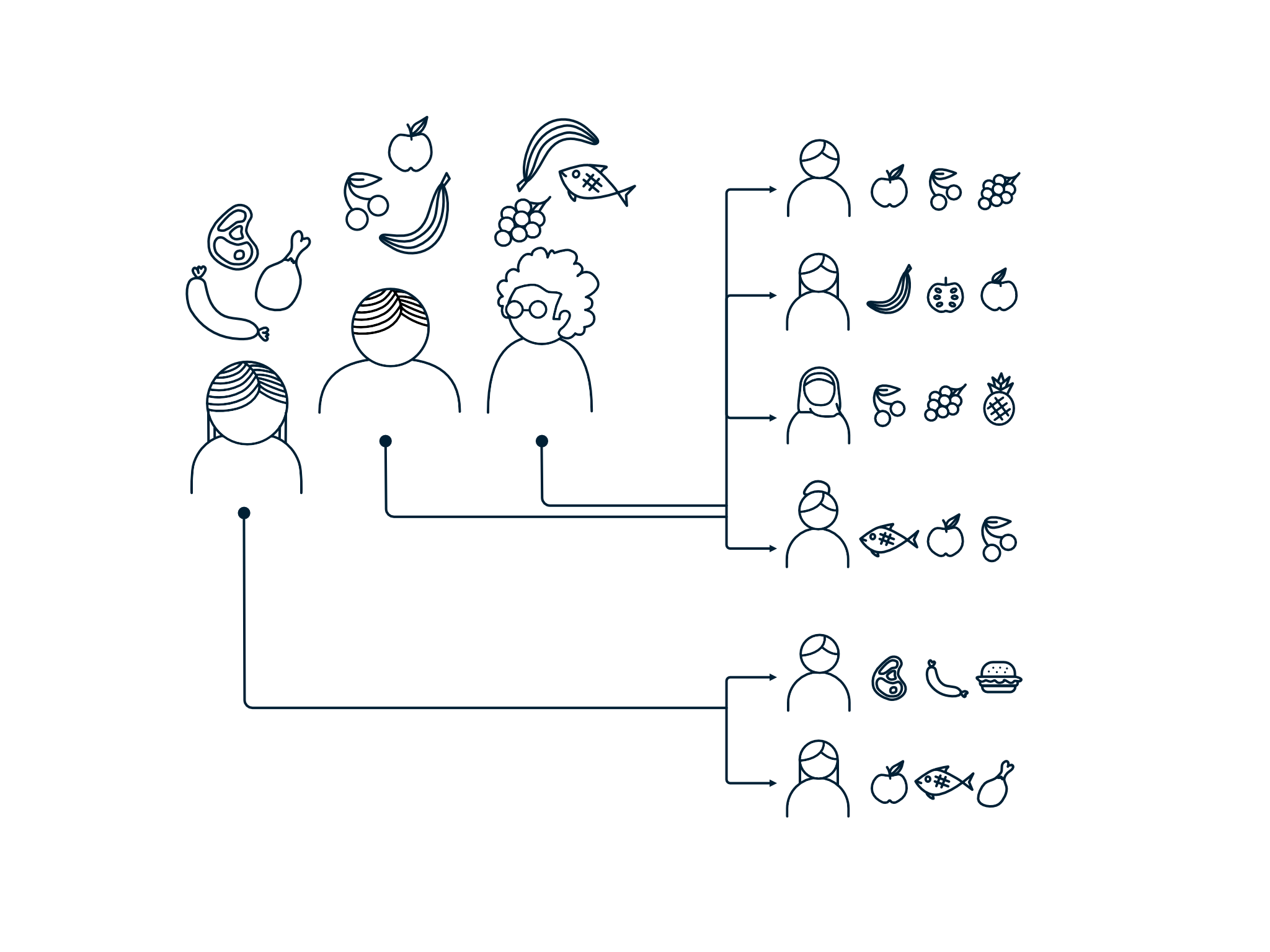
A user profile is realistic if it could happen in the real world. If you generate user profiles completely at random, then your recommendation model can only learn to give random predictions. Some purchase histories are more probable than others. You can learn basic customer behavior from a (very limited) amount of user data to make sure that your generated user profiles resemble real user profiles close enough.
Final words
For other, more rare domains, augmentations may be considered with the aid of domain experts. What are the relevant distinguishing features of the data? Which targets should be distinguished in the first place?
In practice, even if your data isn't perfect, there is a good chance that machine learning can still be used to solve your problem. It is possible we can work out a way to generate more data for you as the project progresses, and give good estimates on how much more data would be needed in general.
Check out our website to learn more about our expert data science team and reference projects. Or click here to go to our contacts page where you approach us for any data-related needs or ideas.
Further reading elsewhere:
https://machinelearningmastery.com/best-practices-for-preparing-and-augmenting-image-data-for-convolutional-neural-networks/
pic: https://www.kdnuggets.com/2018/05/data-augmentation-deep-learning-limited-data.html
Emblica is a technology company focused on data-intensive applications and artificial intelligence. Our customers are e.g. Sanoma, Uponor, Caruna, and the Tax Administration. Emblica is 100% owned by its employees.